MindJourney: Test-Time Scaling with World Models for Spatial Reasoning
MindJourney: Test-Time Scaling with World Models for Spatial Reasoning
- 2025.07
- UMass Amherst, JHU, HKUST, Microsoft Research, Harvard
- https://github.com/UMass-Embodied-AGI/MindJourney
한줄 요약: 월드모델 + test-time scaling
Abstract
- 최신 vlm의 발전, 하지만 2d 인식에 머무르고 3d 변화 (시점 이동 후 장면 변화)는 예측 x
- 이를 해결하기 위해 새로운 프레임워크 MindJourney 제안함
- 비디오 diffusion 기반의 controllable 월드 모델을 VLM과 결합해서 이 한계를 보완함
- VLM은 간단한 카메라 이동 경로를 반복적으로 생성2
- 월드 모델은 각 단계에서 그 시점의 이미지를 생성함
- VLM은 생성된 멀티뷰 정보를 기반으로 추론을 수행함
- 비디오 diffusion 기반의 controllable 월드 모델을 VLM과 결합해서 이 한계를 보완함
- 결과
- 별도의 학습 없이도, mindjourney는 대표적인 spatial reasoning 벤치마크인 SAT에서 평균 7.7% 성능 향상을달성함
- 월드 모델을 test-time에 결합하는 방식이 간단하면서도 효과적인 3d 추론 개선 방법임을 보여줌
- 또한 이 방법은 강화학습으로 test-time inference를 학습한 vlm보다도 더 나은 성능을 보임 → 월드 모델 기반 test-time scaling의 잠재력을 입증함
Method
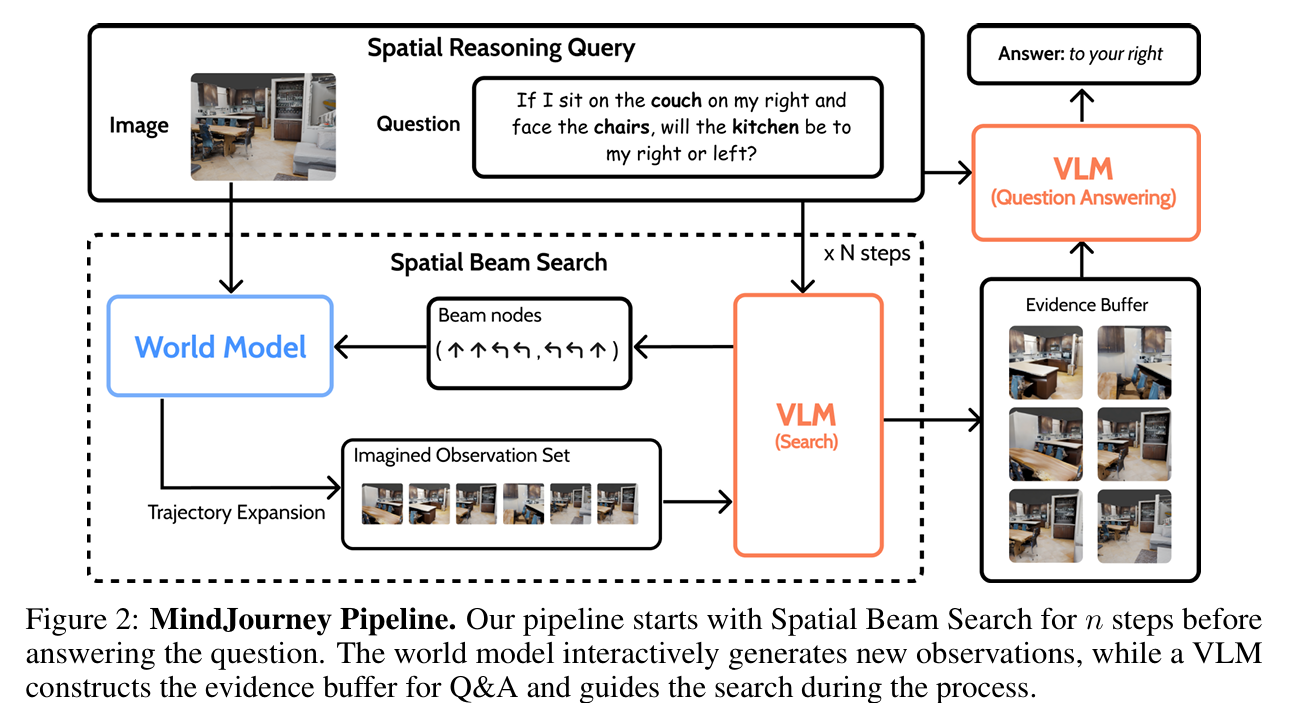
- 3.1. overview
- 목표: 월드 모델의 예측 능력을 활용해서 vlm의 3d 공간 추론 성능을 test-time에서 향상시키는 것을 목표로 함
- 제안하는 mindjourney 프레임워크는 2가지 핵심 구성 요소로 이루어짐
- 비디오 디퓨전 기반 월드 모델
- 입력: 하나의 rgb 이미지와 카메라 pose로 정의된 egocentric 행동 시퀀스
- 출력: 해당 경로를 따라 일관된 시점 변화 영상을 생성함
- Spatial Beam Search
- 주어진 question을 기반으로 vlm과 월드 모델이 상호작용 하며, 유용한 시점 경로를 탐색하는 과정임
- 비디오 디퓨전 기반 월드 모델
- 과정
- 입력: 이미지, question
- 모델이 n-step spatial beam search 수행
- 현재 beam에 포함된 각 trajectory에 대해 월드 모델이 새로운 후보 trajectory와 해당 시점의 관측 이미지를 생성함
- search VLM은 question을 조건으로 이 관측 결과들을 평가
- 답변에 도움이 되는 trajectory-observation 쌍을 helpful observation buffer에 저장
- 추가 탐색이 가치 있는 trajectory만 선택해서 다음 단계의 beam으로 넘김
- 탐색이 종료되면, qa vlm은 원본 이미지와 버퍼에 저장된 관측 정보를 사용해서 최종 답변 생성
- 3.2. World Model Formulation
- 본 연구에서
- 월드 모델: 기준 이미지로부터 시작해서 일련의 행동을 순차적으로 전개하는 egocentric 시뮬레이터로 정의함
- action space는 이동과 회전으로 구성 - 앞으로 이동, 좌회전, 우회전
- 이런 action들을 순차적으로 나열한 것이 trajectory
- τ = (a₁, …, aₘ)
- 길이가 m 이하인 모든 trajectory의 집합을 탐색 공간으로 정의함
- 이 action들은 카메라의 상대적인 pose 변화로 변환
- 카메라 pose 시퀀스 C = (c₁, …, cₘ)
각 pose는 카메라의 intrinsic matrix K와 extrinsic matrix E = [R t]로 표현 - 이 pose 정보를 조건으로 적용해서 비디오 디퓨전 기반 월드 모델이 각 시점의 이미지를 생성함
- 실제 동작
- (입력 이미지, trajectory로부터 생성된 pose 시퀀스) → 월드 모델→ 영상 시퀀스 생성
- 본 연구에서
- 3.3. Spatial Beam Search for Action Space Exploration
- trajectory의 길이가 길어질 수록 가능한 경우의수도 기하급수적으로 늘어남
- 이를 효율적으로 탐색하기 위해 beam search를 사용함
- 2단계의 반복
- 질문과 무관하게 **후보를 확장하는 단계**
- 질문을 고려해서 **후보를 제거하는 단계**
- 전체 탐색은 최대 n step동안 진행
- 각 step마다 현재 beam에 있는 trajectory들을 확장한 뒤 vlm을 사용하여 공간 질문에 대한 관련성을 기준으로 점수를 매김
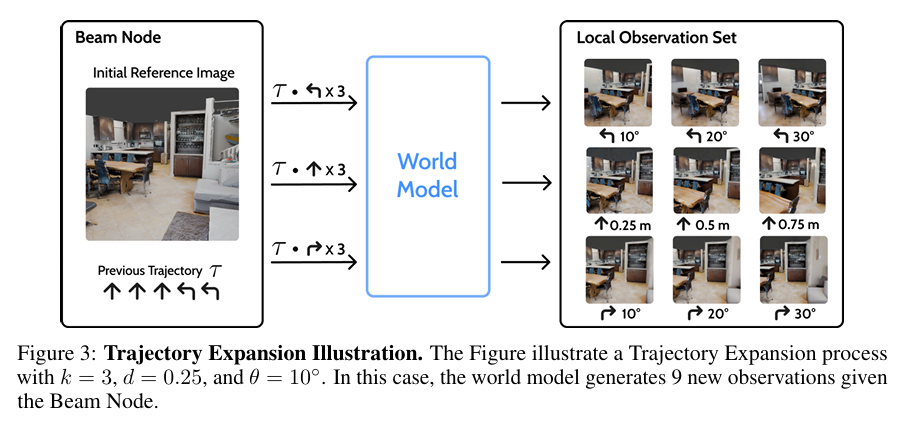
- 각 beam node는 길이 m의 trajectory를 저장함
- 이 node에서 탐색을 확장하기 위해, 각 primitive action a’에 대해 최대 k번까지 반복 적용
- 한번에 최대 k개의 action을 붙임
- 생성된 후보는 월드 모델에 입력되어 해당 시점의 이미지들을 만듦
- 이 node에서 탐색을 확장하기 위해, 각 primitive action a’에 대해 최대 k번까지 반복 적용
- 각 후보에 대해 자연어 설명을 생성하고, 질문 q와 함께 vlm에 입력
- vlm은 점수를 출력
- 해당 trajectory를 계속 탐색할 가치가 있는지
- 현재 이 시점이 답을 도출하는 데 얼마나 도움이 되는지
- 일정 threshold 이하의 후보는 제거
- 남은 후보 중에서 기준 1 상위 B개는 다음 step의 빔으로 유지, 기준 2 상위 H개는 유용한 관측 정보로 판단되어 evidence buffer에 저장됌
- vlm은 점수를 출력
- 이 과정을 n step 반복 or 더 이상 후보가 없을 때 종료
buffer에 저장된 모든 유용한 trajectory와 그에 대응하는 이미지, 설명을 모아 vlm에 입력하면 vlm은 이를 기반으로 최종 답변을 생성함
- 3.4. Search World Model Details
- Search World Model이라는 자체 월드 모델을 학습함
- Wan2.2-TI2V-5B 모델을 기반, ReCamMaster 방식을 따름
- 카메라 변환은 extrinsic matrix 형태로 표현
- 이를 임베딩하여 video latent에 픽셀 단위로 직접 더하는 방식으로 반영
- 학습 데이터
- Habitat 2.0 네비게이션 시뮬레이터를 통해 합성
- Habitat은 실내 환경에서 전진, 후진, 회전 등의 움직임에 대해 픽셀 수준으로 정확한 렌더링을 제공함 → 정밀한 카메라 제어 학습에 적합함
- 합성 데이터의 단점을 보완하기 위해 RealEstate-10K와 DL3DV-10K와 같은 실제 영상 데이터셋을 함께 사용
- habitat의 기하학적 정확성과 실제 데이터의 시각적 다양성을 결합
- **합성 환경을 넘어 실제 환경에서도 잘 일반화되는 월드 모델을 학습함**
- Search World Model이라는 자체 월드 모델을 학습함
Experiments
- 4.1. Settings
- 벤치마크
- SAT (Spatial Aptitude Training) 벤치마크
- egocentric 자기 자신 움직임, 물체 움직임 모두 평가함
- SAT-synthesized / SAT-real
- 객관식 → 정확도로 평가
- 5가지 공간 추론 문제
- EgoM: egocentric 움직임 / “내가 움직이면 장면이 어떻게 변하나”
- ObjM: 객체 움직임 / “객체가 움직이면 어떻게 변하나”
- EgoA: 행동 결과 추론 / “특정 행동의 결과는 무엇인가”
- GoalAim: “특정 목표를 향해 이동하거나 행동했을 때, 그 결과가 어떻게 될지 예측”
- Pers: 시점 변화 / “시점이 바뀌면 어떻게 보이나”
- VLM
- gpt-4o, gpt-4.1, internVL3-14B, o1
- 월드 모델
- 본 연구에서 학습한 swm
- SVC
- spatial beam search
- 탐색 깊이 n = 3
- primitive action k = 3
- 기준 1, 2 점수 threshold 둘 다 8
- 벤치마크
4.2. Results
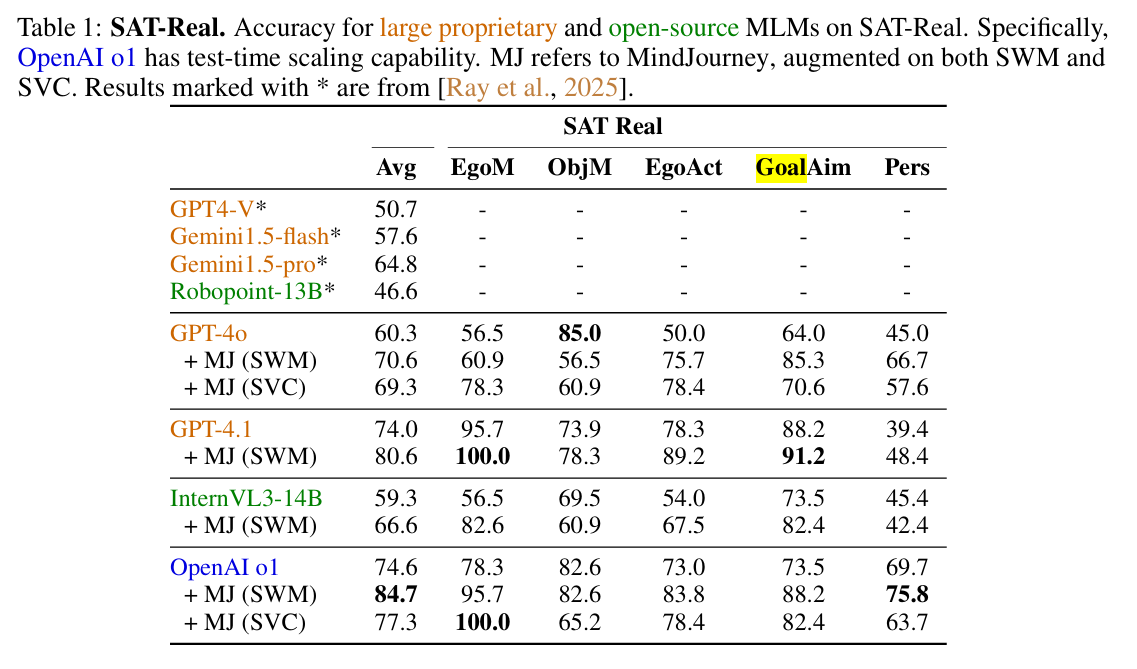
- SAT-Real: 실내외 실제 이미지 150개
- 모든 vlm에 mindjourney를 적용했을 때 일관되고 큰 폭의 성능 향상이 나타남
- o1에 mindjourney를 결합햇더니 sota를 달성함
- 월드 모델 기반 test-time scaling이 rl 기반 scaling과 상호보완적이며, 실제 환경에서도 잘 일반화된다는 것을 보여줌
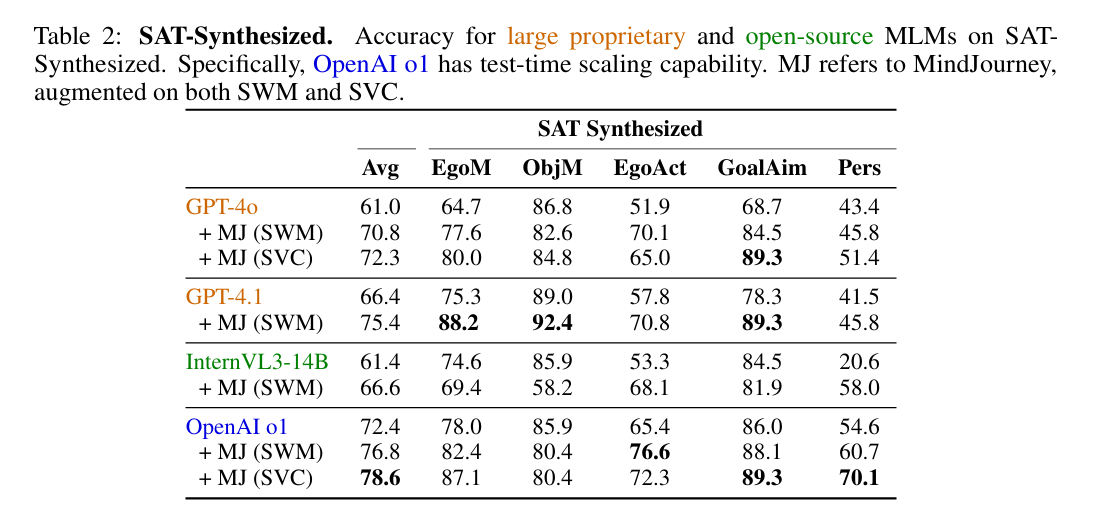
- SAT-Synthesized: 4000개 질문, o1 실험의 계산 비용을 고려해서 500개를 샘플링해서 평가함
- 마찬가지로 mj 결합했더니 평균 정확도가 올라감
- 모든 SAT task에서 최고 성능은 항상 mj 적용한 모델이 기록
- MJ는 특정 task에 국한되지 않고 전반적인 공간 추론 능력을 일관되게 개선함 ~~
- SAT-Real: 실내외 실제 이미지 150개
- 4.3. Ablation Study
- 제안한 탐색 방법의 하이퍼파라미터가 성능에 미치는 영향 분석
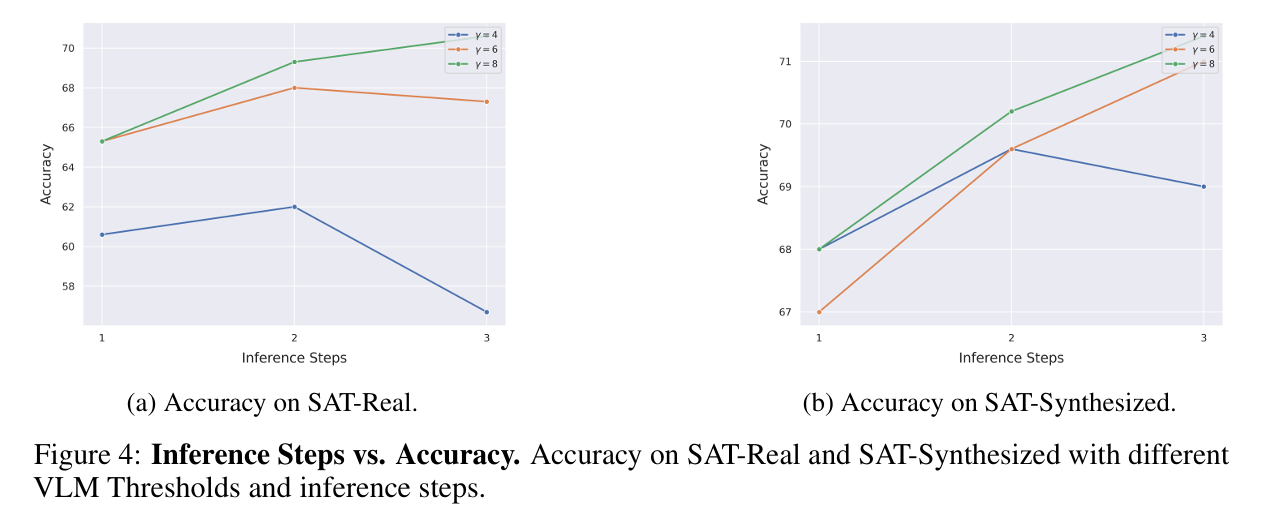
- gpt-4o + swm 조합
- 탐식 깊이 n = [1, 2, 3], pruning threshold γ ∈ {4,6,8}
- SAT-Real
- threshold 4와 6일 때 step 2에서 최고점
- trajectory가 길어지면 생성 품질이 떨어짐
- SAT-Synthesized
- 학습 분포랑 유사해서
- trajectory가 길어져도 성능이 향상
- 월드 모델이 정확하게 long rolllout을 생성할 수 있는 경우에는 deeper exploration이 여전히 유효함
- pruning threshold
- threshold가 낮으면 정확도 떨어짐
- 특히 sat-real에서 두드러짐
- 실제 이미지에서 생성된 뷰의 품질이 상대적으로 낮기 때문에 필터링의 중요성이 더 커짐
- 4.4. Analysis
- 월드 모델 기반 test-time scaling vs RL 기반 test-time scaling
- 단순 vlm에 월드 모델 기반 탐색을 추가 > o1 모델 (rl 기반 finetuning)
- o1에 월드 모델 기반 탐색 추가 → 성능 개선
→ 월드 모델이 제공하는 탐색 정보가 rl에서 학습한 cot와는 다른 서로 보완적인 정보임을 의미함
- 물리적으로 일관된 상상 공간을 제공하는 것이 기존의 reasoning 능력을 대체하는 것이 아니라 오히려 강화하는 역할을 함
- 월드 모델의 성능
- trajectory가 길어지면 world model의 생성 품질이 급격하게 저하되는 현상…
- 이게 전체 추론 능력에도 방해를 함
- 더 긴 trajectory를 효과적으로 활용하기 위해서는 기하적, 시간적 일관성을 유지할 수 있는 더 강력한 월드 모델이 필요함
- 월드 모델 기반 test-time scaling vs RL 기반 test-time scaling
Conclusion
- 요약
- mindjourney: test-time에서 월드 모델을 활용하여 VLM에 상상 능력을 부여하는 최초의 프레임워크
- spatial beam search를 통해 vlm은 하나의 이미지 뒤에 존재하는 잠재적인 3d 공간을 능동적으로 탐색, 공간 추론에 가장 유용한 시점들을 선택적으로 저장함
- 이렇게 학습없이 간단한 방법으로 여러 vlm을 사용해서 sat 벤치마크에서 sota 달성
- 공간 추론 문제에서는 단순히 추론 능력을 강화하는 것보다, 물리적으로 일관된 시뮬레이터를 test-time에 제공하는 것이 rl 기반 self-reflection 방식과 상호 보완되거나 이를 능가할 수 있음을 보여줌
- 한계
- **하나의 이미지만을 입력으로 가정함**
- 여러 이미지가 주어지는 경우, 이를 각각 독립적인 탐색 시작점으로 활용 x
- multi-view 입력을 처리할 수 있도록 spatial beam search를 확장하는 것이 향후 연구 방향
- **현재 비디오 기반 월드 모델은 질문을 고려하지 않고 시점을 생성한다는 한계**
- query-conditioned world model을 개발하거나, 생성 과정에 제약을 추가해서 질문과 일관된 시점만 생성하도록 하는 방법이 필요함
- **하나의 이미지만을 입력으로 가정함**
Appendix - B. Failure Case Analysis

- Case A
- forward movement의 부정확성
- 생성된 trajectory가 전진 거리를 과소, 과대 추정하는 문제
- 의도한 이동 거리 ≠ 실제 생성된 이동
- 프레임 간 이동량도 불규칙하게 변함
- 원인: 학습 데이터 간 스케일 불일치
- SVC는 다양한 데이터셋을 사용하며 다른 스케일 기준을 가짐
- forward movement의 부정확성
- Case B
- 생성된 이미지가 비정상적으로 기울어지는 문제
- 수평선에 어긋나 있음 → 카메라가 의도하지 않은 roll 회전을 수행함
- Case C
- egocentric 회전 과정에서 시점이 불안정하게 변함
- 회전하면서 동시에 오른쪽으로 이동하는 것처럼 보임
- 특히 swm에서 많이 발생 - realestate 10k를 섞어서 학습했기 때문
- 해당 데이터에는 이동과 회전이 동시에 일어나는 경우가 많음 → 편향을 학습
- Case D
- 생성된 이미지에 시각적 artifact가 나타남
- 충분한 시각적 정보가 없는 영역을 생성할 때 약한 prior나 잘못된 패턴에 의존
- Case E
- out-of-domain의 장면에서 구조를 잘못 해석하는 문제
- 다양한 환경을 충분히 학습하지 못해 일반화 성능이 부족하기 때문임
- Case F
- 사람이나 동물과 같은 복잡한 객체를 제대로 생성 못함
- 변형 가능한 구조에 대한 학습 데이터 부족
This post is licensed under CC BY 4.0 by the author.