SpatialRGPT: Grounded Spatial Reasoning in Vision-Language Models
SpatialRGPT: Grounded Spatial Reasoning in Vision-Language Models
- NIPS 2024
- UC San Diego, Nvidia
Abstract
- VLM의 공간 추론 능력을 향상시키기 위해 spatial region GPT를 제안함
- 2가지의 핵심 기여를 통해 vlm 공간 이해 능력을 향상시킴
- 3d 장면 그래프로부터 영역 단위 표현을 효과적으로 학습할 수 있도록 하는 데이터 구축 파이프라인
- 기존 vlm 비전 인코더에 depth 정보를 통합할 수 잇는 유연한 플러그인 모듈
- 추론 단계에서 사용자로부터 특정 영역이 주어지면 spatialRGPT는 해당 영역들 간의 상대적인 방향과 거리 관계를 정확하게 인식할 수 있음
- SpatialRGBT-bench라는 벤치마크를 제안 - vlm의 3d 공간 인지 능력을 평가할 수 있도록 함
- SpatialRGPT는 지역 정보가 주어지는 경우/아닌경우 모두 공간 추론 성능을 크게 향상시킴
- 복잡한 공간 관계에 대해서도 강한 일반화 성능을 보임
- 로보틱스 작업에서 region-aware dense reward annotator로도 활용될 수 있음을 확인함

Introduction
- 2d, 3d에서의 공간적 배치를 이해하는 것의 중요성
- 선행연구들
- 공간 정보를 반영한 vqa 데이터셋을 대규모로 생성할 수 있는 데이터 파이프라인 도입
- 이는 기존 vlm이 학습한 데이터에 2d/3d 공간 지식이 부족하기 때문이라는 가설에 기반
- 문제점은…
- (1) 공간 추론을 위해서는 객체 인스턴스 수준의 지역 정보를 파악해야 하지만, 기존 vlm은 주로 이미지의 전역적 맥락을 이해하도록 설계
- (2) 공간 관계를 정확하게 인식하기 위해서는 depth와 같은 3d 정보가 모델 구조에 포함되어야 함
- 데이터 구축 파이프라인과 region/3d 정보를 반영한 비전 인코더를 활용하는 SpatialRGPT를 제안
- 데이터 구축 파이프라인
- 각 이미지에 대해 3D 장면 그래프를 구성 - 이미지로부터 3D 기반 region-aware annotation 대규모로 자동생성
- 노드: 객체, 엣지: 공간 관계
- open-vocab 객체 탐지 및 segmentation을 통한 객체 추출
- metric depth 추정
- 객체를 3d 공간으로 투영하기 위한 카메라 보정
- 이렇게 생성된 데이터 → 템플릿/llm 기반 방법 → region-aware spatial QA
- vlm이 복잡한 환경을 이해하는데 필요한 공간 지식과 고급 추론 능력을 학습 가능하게 함
- spatialrgpt를 이 데이터로 학습함
- region prompt를 지원해서 spatialVLM에서 생기는 모호성 문제를 해결함
- 유사한 객체가 있을 경우 캡션이 혼동되는 문제
- region proposal을 이미지와 함께 입력으로 사용하는 region representation 모듈을 도입
- 이를 통해 llm은 전역과 지역 정보를 동시에 활용 가능
- 전체 장면을 이해하면서 특정 영역 간 관계를 추론할 수 있음
- 비전 인코더에 상대적 depth 정보를 통합할 수 있는 플러그인 구조를 제안함
- depth 입력이 있을 때 없을 때 모두 동작함
- depth 입력이 존재하면 이를 활용해 추가적인 표현을 학습 → 공간 추론 성능을 크게 향상
- spatialRGPT는 region-aware dense reward annotator로 활용, 독립적인 복잡한 공간 추론 모델로 사용될 수 있음을 보임
- 본 연구의 기여점
- SpatialRGPT를 제안 - 지역 수준의 공간 추론을 강화, 지역 정보 표현과 공간 지식 학습을 효과적으로 가능하게 함
- depth 정보를 유연하게 통합해서 3d 인지 성능을 크게 향상시킴
- 기존 데이터셋으로부터 region-aware spatial qa를 생성하는 확장 가능한 데이터 파이프라인을 제안함
- 500만 개 이상의 영역에서 870만개의 공간 개념을 포함하는 open spatial dataset 구축
- 벤치마크 spatialRGPT-Bench 제안
- SpatialRGPT의 실제 활용 가능성 제시 - 로보틱스를 위한 region-aware dense reward annotator로서의 활용과, 독립적인 복잡한 공간 추론 모델 및 multi-hop reasoning 능력 보여줌
- SpatialRGPT를 제안 - 지역 수준의 공간 추론을 강화, 지역 정보 표현과 공간 지식 학습을 효과적으로 가능하게 함
Related Work
- llm을 통한 공간 추론
- 3d 피처 + llm: 정확하지만 무겁고 모달리티 갭 있음
- conceptgraph: 3d 피처를 바로 llm에 입력 x, 장면 그래프를 만든 뒤 이를 llm과 결합
- 구조는 좋지만 llm이 좌표 이해 못함
- spatialVLM : 가볍지만 실제로는 언어 prior에 의존
- region-level VLM
- KOSMOS-2 [24], Shikra [25], MiniGPT-2 [26], CogVLM [27], SPHINX [28], LLaVA [29]
- bbox 사용 - 배경 포함 - noisy
- 좌표 텍스트는 llm이 제대로 못 씀
- 본 연구는 regionGPT 기반으로 region-level + 실제 공간 추론 강화
Method
- SpatialRGPT는 region을 입력 받아서 공간 추론을 수행함
- 본 연구에서는
- **단일 이미지로부터 3d 장면 그래프를 구축하는 방법**
- **이러한 장면 그래프로부터 시각적 표현 학습을 수행하는 방법**
- **2d vlm에 depth를 통합할 수 있는 비전 인코더 구조**
3.1. 3D scene graph from single 2d images
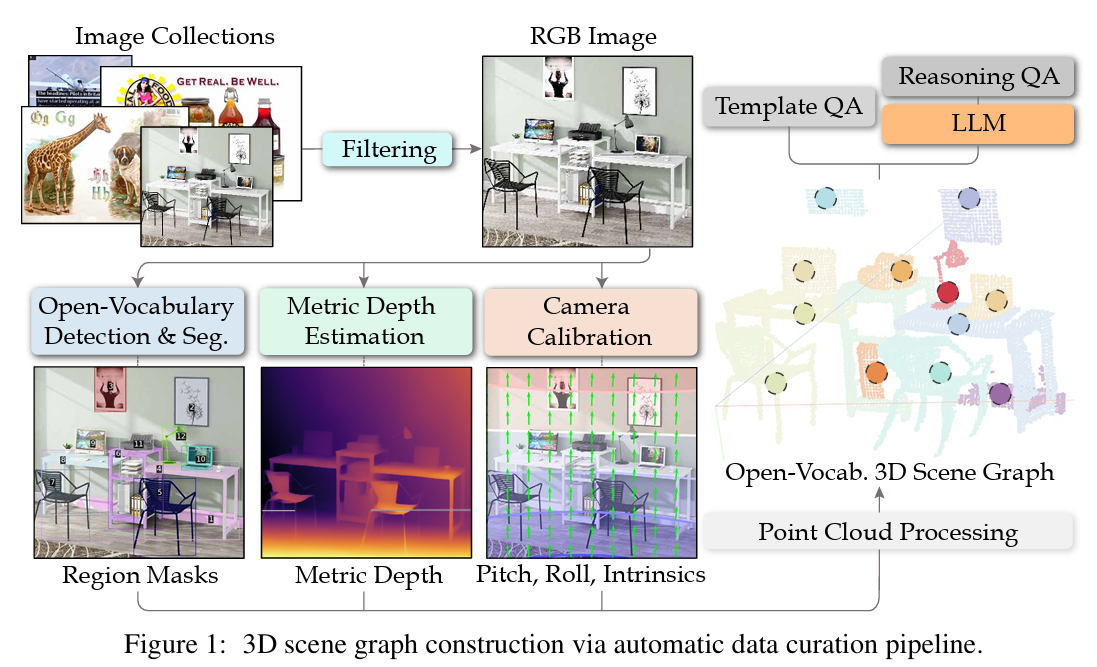
- Open-vocab detection & segmentation
- open-vocab 이미지 태깅 모델로 이미지 내 객체 클래스를 식별함
- groundingDINO를 사용해 객체의 bounding box를 얻음
- segmentation 모델을 통해 정밀한 mask로 변환함
- Metric depth estimation
- Metric3Dv2는 focal length를 입력으로 사용하며 다양한 환경에서 학습
- metric3dv2와 wildCamera의 카메라 intrinsic을 함께 사용해서 실제 환경 이미지에서도 robust한 depth를 얻음
- depth랑 normal을 함께 학습하기 때문에 객체 경계에서 기하 구조가 개선됨
- Camera Calibration
- depth map을 3d point cloud로 변환하기 위한 intrinsic 추정
- WildCamera
- scene을 공통 좌표계로 정렬하는 canonicalization
- PerspectiveFields
- 사진 찍힌 각도 차이를 보정해서, 모든 장면을 비슷한 기준축 위에서 비교 가능하게 만드는 과정
- depth map을 3d point cloud로 변환하기 위한 intrinsic 추정
- 3D 장면 그래프 생성
- 노드는 객체 클래스, 엣지는 관계로 구성
- 노드 생성 과정
- instance mask로 depth에서 객체 포인트 추출
- 픽셀을 3d 공간의 포인트로 올리기
- canonicalization 및 노이즈 제거
- 3d axis-aligned bounding box 생성
- 실제 크기 계산 - width, height 등
- 엣지
- 상대 관계 : 왼쪽, 오른쪽, wide, thin…
- metric 관계 : 방향, 직선 거리, 수평 거리, 수직 거리 등 “수치”
- Open-vocab detection & segmentation
- 3.2. Learning Spatial-aware VLMs from 3D scene graph
- 생성된 3d 장면 그래프를 vlm 학습을 위한 텍스트 표현으로 변환하는 방법
- 미리 정의된 템플릿 방법은 질문 다양성이 제한되고 모델의 추론 능력을 저하시킬 수 있음

- 템플릿 기반 qa
- 기본적인 공간 지식을 학습하기 위한 기반 역할
- 노드의 속성과 엣지의 속성을 추출
- 각 속성에 대해 정성적, 정량적 템플릿을 만들어 질문/답 생성
- 객체는 region [X] 형태로 표현
- llm 기반 복잡 추론 qa
- llama3-70b를 사용해서 복잡한 공간 추론 질문을 생성함
- 장면 그래프를 그대로 llm에 넣으면 3d 좌표를 잘 활용 x
- 장면 그래프에서 속성을 추출해서 템플릿 기반으로 자연어 형태의 spatial description을 생성함
- 이 설명과 region 태그를 llm의 입력으로 넣음 → 이를 기반으로 llm이 복잡한 추론 질문과 답을 생성 - OpenImages 데이터셋을 사용해 자동 annotation 파이프라인 사용 - 결과적으로,
- Open Spatial Dataset (OSD)를 구축
- _**100만 이미지**_
- _**500만개 region**_
- _**800만개 템플릿 기반 qa**_
- _**70만개 llm 기반 qa**_
3.3. VLM 아키텍쳐
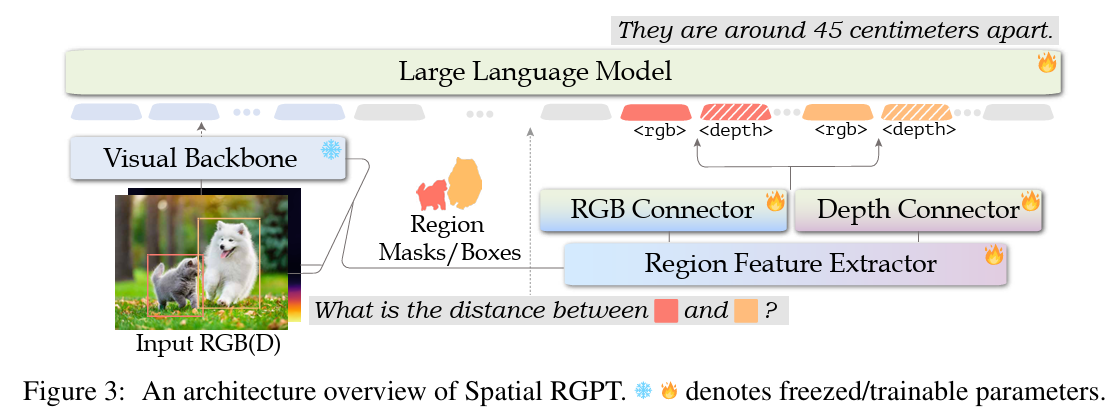
- 구성
- visual encoder
- region-feature extractor: region-level 임베딩
- linear connector: 멀티모달 임베딩 → 단어 임베딩 projection
- LLM: llama2-7b 기반
- 상대적인 depth 입력을 위한 플러그인 모듈
- rgb만 사용하는 vlm은 3d 인지 작업에 한계가 있고, 3d 데이터를 직접 사용하는건 스케일 및 데이터 다양성 문제로 어려움
- 이를 해결하기 위해 기존 모델로부터 얻을 수 있는 relative depth를 rgb와 함께 입력으로 사용함
- 목적은 _**depth를 통해 기하학적 추론 능력을 유도**_하는 것
- depth 정보를 자연스럽게 통합하는 추가 모듈 설계
- depth map도 동일한 이미지 인코더로 피처 맵 생성
- depth 전용 connector를 통해 언어 공간으로 projcetion
- 이 connector는 spatial QA에 대해서만 학습
- Depth 정보 유/무 모든 케이스에 동작 (없어도 동작, 있으면 성능 향상)
- 토큰화 및 프롬프트 구조
- 멀티턴 대화형태 데이터
- 입력:
+ text + +
- 구성
- 3.4. 학습 및 추론
- 학습은 3단계
- coonector feature 정렬
- CC3M 이미지-캡션 데이터
- RGB connector
- visual language 사전학습
- MMC4, COYO - 대규모 비전언어 데이터, region 이해 데이터, OSD (본문) 데이터
- llm, connector
- visual instruction tuning (최종 추론 학습)
- vlm 전체 finetuning
- instruction tuning 데이터, region-level instruction 데이터, OSD 데이터
- coonector feature 정렬
- region-level 데이터와 OSD를 학습할때는 각 샘플마다 box, mask 등 서로 다른 입력 형태를 랜덤으로 선택 → 모델이 다양한 입력 형태에 대응할 수 있도록 함
- 추론 시 spatialRGPT는 box, mask 입력을 모두 사용할 수 있음
- 본 연구의 실험에서는 seg가 존재하면 mask, 아니면 bbox를 입력으로 받아 SAM을 사용해 마스크를 생성한 뒤 사용함
- 학습은 3단계
Experiments
- spatialRGPT를 3 측면에서 평가함: 공간 추론 벤치마크, 일반 vl 벤치마크, 실시간 응용
- 4.1. 3D 공간 추론 벤치마크
- 현재 공간 추론에 대한 벤치마크 X
- spatialVLM이 벤치마크 만들었는데 공개 x
- SpatialRGPT-Bench라는 자체 벤치마크 제안
- 도시 환경, 실내 환경, 시뮬레이션 환경의 데이터 포함
- 다양한 객체, 환경 포함
- Omni3D에서 제공하는 3d cuboid annotation 활용해서 동일한 카메라 좌표계로 정렬
- 이 정보를 바탕으로 대화 형태의 spatial VQA 벤치마크를 구성함
- 벤치마크
- 정성적 QA 657개
- 정량적 QA 749개
- 클래스 88개
- 베이스라인 모델
- Blind llm (언어만 사용): 질문 텍스트만으로 답변, gpt-4
- vlm + language 참조: gpt4v, llama-v1.6-34b
- region-aware vlm: gpt-4v + SoM, LLaVA + SoM, KOSMOS-2, RegionVILA
- 평가방식
- 정성적 QA: GPT-4가 정답과 일치 여부를 0/1로 평가
- 정량적 QA: 미터로 단위를 통일해서 정확도를 +- 25%이내의 오차를 두고 계산
- absolute relative error 계산
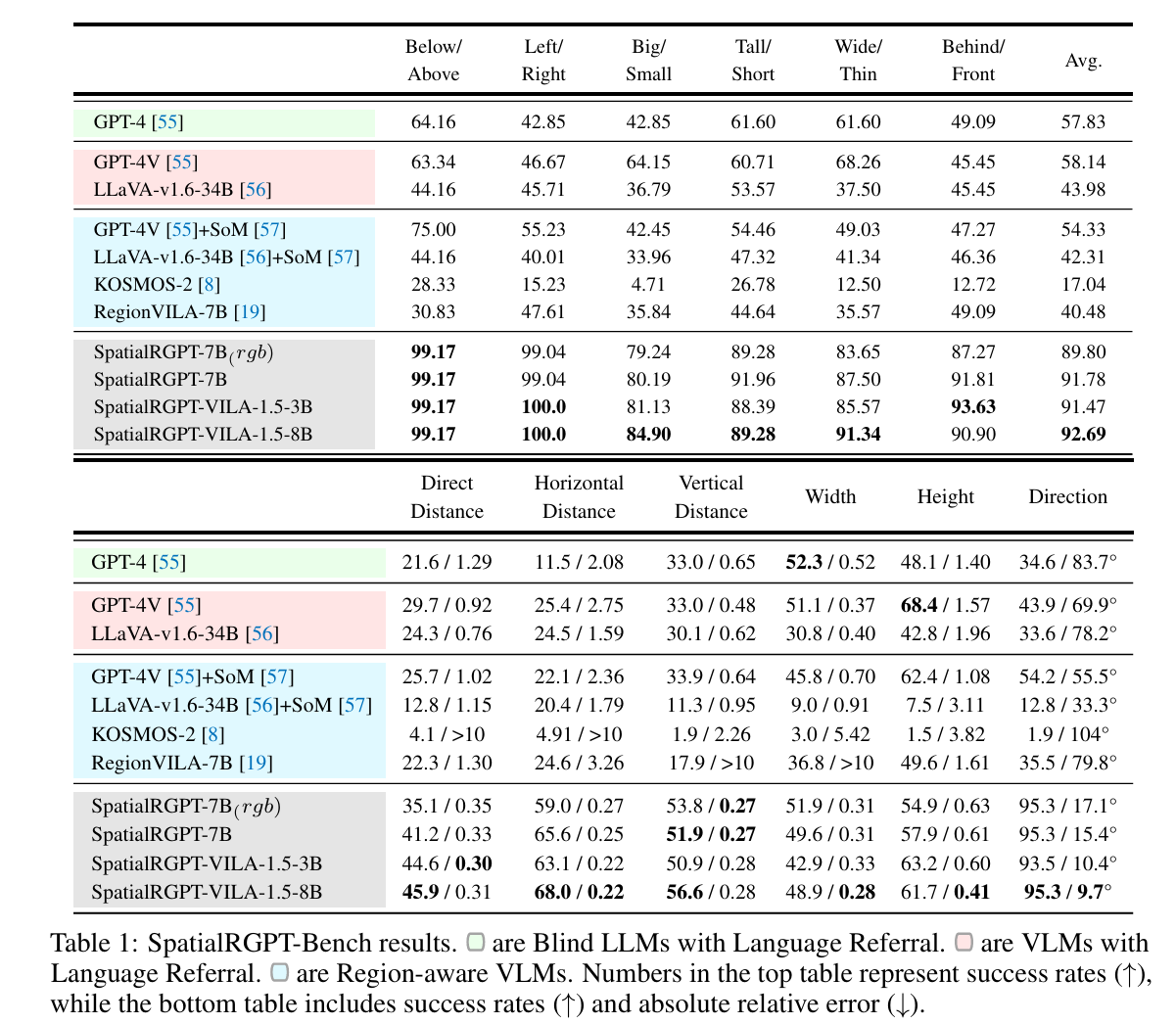
- 결과
- spatial RGPT가 정성적 QA에서 가장 높은 정확도, 정량적에서는 가장 낮은 에러
- 흥미로운것은 blind llm도 너비 높이 같은 질문은 꽤 잘 맞춤 → world knowledge를 활용하기 때문
- depth의 효과 있음 7b > rgb only
- 4.2. 일반 vision-language 벤치마크
일반 벤치마크
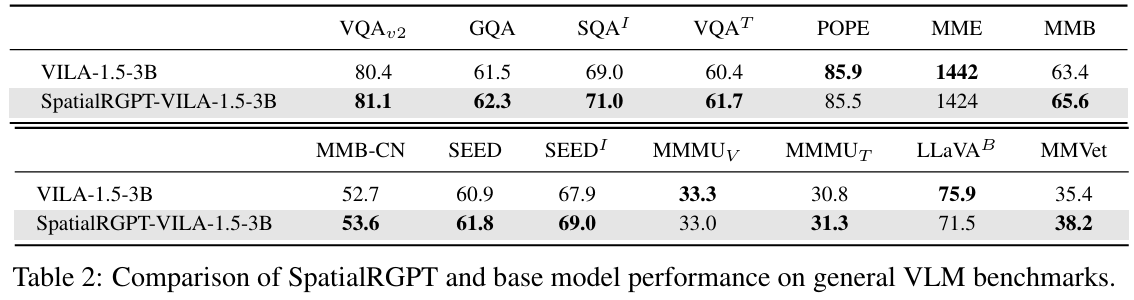
- spatial VQA 데이터와 depth 정보를 추가하는 것이 다른 vqa task에 도움이 되는지를 평가
- 동일한 일반 vqa 데이터로 학습된 VILA-1.5-3B와 비교
- SpatialRGPT는 베이스라인과 유사한 성능을 보이고, 약간 더 높은 성능을 보이는 경우도 있음
- **→ 일반적으로 vlm은 공간 추론에 약하지만, spatial VQA 학습을 추가하면 일반 VQA 성능을 유지하면서 공간 추론 능력을 개선할 수 있음을 보여줌**
Region 및 Spatial 벤치마크
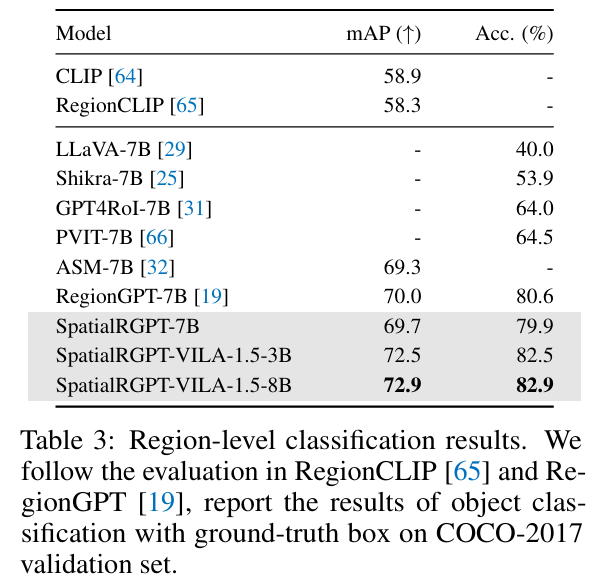
- regionGPT의 평가 프로토콜을 따라 coco-2017 벤치마크에서 gt bbox를 사용해 객체 분류 성능을 평가함
- spatialRGPT는 베이스라인 모델보다 더 높은 성능을 보임 → 강한 region 이해 능력
- BLINK의 relative depth 벤치마크에서 평가를 수행
- 이 벤치마크는 point-level depth를 평가하는 어려운 task
spatialRGPT는 point level 입력으로 학습 x, bbox를 사용해 해당 포인트를 지정해서 평가함

- spatialRGPT는 기존 SOTA 대비 20% 이상의 정확도 향상
- 특히 GPT-4V-Turbo 대비 큰 성능 개선을 이룸
- _**이는 별도의 학습 없이도 새로운 작업에 대한 일반화 능력이 뛰어남을 보여줌**_
- 4.3. Real-world applications
복잡한 공간 추론

- spatialRGPT는 GPT4V와 비교했을 때, 자체적인 공간 지식을 기반으로 복잡한 공간 질문을 해결하는 능력을 보임
- 모델이 공간 정보를 잘 학습했을 뿐만 아니라 그 지식이 언어 추론 능력까지 확장되었음을 보여줌
Multi-hop 추론

- 한번에 여러 단계를 거치면서 추론하는 질문들
- 이런 멀티 스텝 추론은 학습 데이터에 포함 x, spatialRGPT가 공간 관계를 구조적으로 이해하고 있음을 시사함
Region-aware dense reward annotator
- spatial RGPT는 region-aware 기능을 통해 관심 영역을 지정 가능
- 실제 로봇 실험에서 2개의 BBOX를 정의하고, 두 영역 거리 기반으로 reward를 계산하도록 함
손가락이 목표 큐브로 이동할 수록 거리 값이 점진적으로 감소

- spatialRGPT가 region 기반으로 정밀한 reward를 생성할 수 있으며, 언어 기반 방식보다 더 정확하고 효율적인 접근임을 보여줌
## Discussion
- 결론
- VLM의 공간 추론 능력을 향상시키기 위한 새로운 프레임워크인 SpatialRGPT를 제안함
- region representation 모듈과 depth 정보를 위한 유연한 플러그인 통합 → SpatialRGPT는 **vlm이 지역 수준과 전역 수준 모두에서 공간 구조를 효과적으로 인식 가능하게 함**
- 데이터 구축 파이프라인을 통해 장면 그래프로부터 3d 공간 지식을 학습 가능하게 함
- SpatialRGPT-Bench를 통해 다양한 환경에서 공간 인지 능력을 평가할 수 잇는 종합적인 벤치마크를 제공
- 한계
- AABB를 사용한다는 점 → Axis aligned bounding box
- 객체 실제 형태를 정확하게 반영하지 못해 라벨 정확도가 떨어질 수 있음
- 정확한 대안은 oriented bounding box (OBB)
- 이는 정밀한 자세 추정이 필요하고, open world에서는 여전히 어려운 문제임
- 또는 사람이 직접 라벨링 → 많은 비용이 필요함
- future work로 남음
- AABB를 사용한다는 점 → Axis aligned bounding box
This post is licensed under CC BY 4.0 by the author.