When and How Much to Imagine: Adaptive Test-Time Scaling with World Models for Visual Spatial Reasoning
When and How Much to Imagine: Adaptive Test-Time Scaling with World Models for Visual Spatial Reasoning
- 2026.02 arxiv
Abstract
- mllm의 발전, **보이지 않는 시점이나 다른 관점에서 장면이 어떻게 보일지를 고려해야 하는 경우**에는 시각적 공간 추론이 여전히 불안정함
- 이 문제를 해결하기 위해 world model을 활용한 visual imagination을 도입 중
- 언제 imagination이 필요한지, 어느 정도가 적절한지, 언제 오히려 해로운지에 대한 이해는 아직 부족함
- 실제로 imagination을 무분별하게 사용할 경우 계산 비용이 증가할 뿐만 아니라 잘못된 정보를 생성하여 성능을 떨어뜨릴 수 있음
- 이 연구에서는 spatial reasoning에서 test-time visual imagination을 하나의 조절 가능한 자원으로 보고 이에 대한 심층 분석을 수행함
- 정적인 시각정보로 충분한 경우
- imagination이 도움이 되는경우
- 과도하거나 불필요한 상상이 성능과 효율에 어떤 영향을 미치는지를 분석
- AVIC라는 adaptive test-time 프레임워크를 도입함
- 이 프레임워크는 현재 시각 정보가 충분한지를 먼저 판단 후, 필요할 때만 선택적으로 상상을 수행하고 그 강도를 조절함
- 여러 벤치마크에서 평가한 결과,
- 상상이 필수적인 경우, 일부만 도움이 되는 경우, 오히려 해로운 경우가 명확히 존재했음
- 이런 선택적 제어 전략은 고정된 상상 방식보다 훨씬 적은 world 모델 호출과 언어 토큰사용으로도 동등하거나 더 나은 성능을 달성할 수 있음
- 결론적으로, 본 연구는 효율적이고 신뢰성 있는 spatial reasoning을 위해 **test-time 상상을 분석하고 제어하는 것이 중요함을 강조함**
Introduction
- mllm의 발전
- 하지만 visual spatial reasoning은 중요한 도전 과제로 남아있음
- 특히 단일 이미지로 알 수 없는 영역이나 시점 변화, 장면 변형이 필요한 경우에 어려움이 있음
- 자연스러운 접근은 인간처럼 visual imagination을 사용하는 것
- 특히 관측 정보가 부족할 때 다른 시점에서 장면이 어떻게 보일지를 시뮬레이션
- 기존 연구들은 상상을 항상 하거나, 고정된 방식으로 반복적으로 수행함
문제: 불필요한 시점 생성, 잘못된 시점 생성, 계산 비용 증가..

- 보다 적응적인 접근이 필요함!
- rq 2개
- 언제 상상을 해야하는가?
- 얼마나 많은 상상이 필요한가?
- rq 2개
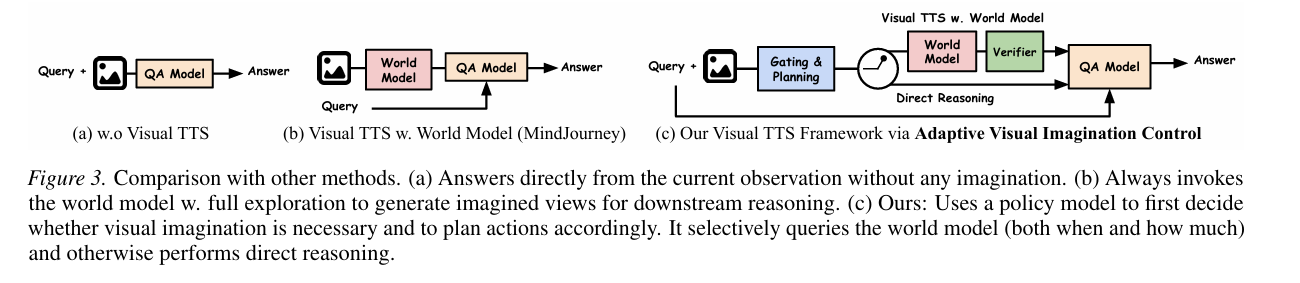
- 이를 위해, 항상 상상을 하는 것이 아니라 test-time에서 조절 가능한 요소로 다루는 AVIC (Adaptive Visual Imagination Control)을 제안함
- 먼저 policy model이 현재 시각 정보가 충분한지를 판단
- 충분하면 상상 없이 바로 답
- 부족하면 어떤 방식으로 시점을 이동하거나 변환할지를 포함한 action plan을 생성함
- 이 계획에 따라 world model이 새로운 시점을 생성하고, 이를 기반으로 최종 추론 수행
→ 상황에 따라 상상을 선택적으로 사용
- 평가 결과 AVIC는 기존 방법 대비 더 적은 월드모델 호출과 토큰 사용으로 비슷하거나 더 나은 성능을 달성함
- visual 상상은 항상 사용하는 기능이 아니라, 문제에 따라 선택적으로 사용하는 자원이며, 이를 적응적으로 제어하는 것이 중요함
Related Work
- Visual Spatial Reasoning with MLLMs
- 시각적 인식과 실제 행동을 연결하는 핵심 요소로서 공간 추론이 중요한 연구 주제로 부상함
- 현재의 mllm은 여전히 안정적이고 정확한 공간 추론 능력에서는 한계를 보임
- 이를 개선하기 위한 연구들
- 데이터 규모 확장
- cot 등 추론 유도 기법
→ 근본적으로 이미지를 정적인 2d 이미지로 처리한다는 한계
- 하지만 실제 공간 추론은 능동적으로 추가 정보를 탐색하고, 상황을 동적으로 상상하는 과정이 필요함
- 월드 모델과 시각적 상상
- 최근 비디오 생성 기술의 발전은 월드 모델로서의 가능성을 보여주고 있음
- 미래 장면이나 결과를 상상해서 의사결정을 돕는 방식
- 특히 **제어 가능한 비디오 생성 기술**은 특정 행동에 따른 결과를 시뮬레이션 가능하게 함
- mindjourney: 새로운 시점을 생성하여 공간 추론 성능을 향상시키는 접근을 제시함
- 난이도나 필요성과 관계없이 항상 일정한 수의 시점을 생성하는 한계가 있음
- Test-time scaling: 모델 재학습 x, 추론 시 계산량을 늘려 성능을 향상시키는 방법
- self-consistency, 트리 기반 탐색, verifier 방법, multimodal cot 등
- 공간 추론에서는 새로운 시점을 생성하고, 이를 앙상블하는 방식이 사용됨
- 대부분 모든 입력에 동일한 계산을 적용한다는 비효율이 있음
- 최근 비디오 생성 기술의 발전은 월드 모델로서의 가능성을 보여주고 있음
Analysis of Always-on World Model Calling
- 기존 방식의 문제점
- always-on visual imagination
- 이 방법은 “상상은 항상 도움이 된다”라는 걸 전제로 하지만 실제로는 그렇지 않음
- 월드 모델 호출은 계산 비용이 크고
- 생성된 뷰가 정확하지 않을 수 있음
- 실험 분석
- case 1 helpful
- case 2 misleading
- 월드 모델이 잘못된 정보 생성해서 답 틀림
- case 3 unnecessary
- 상상 없이도 정답
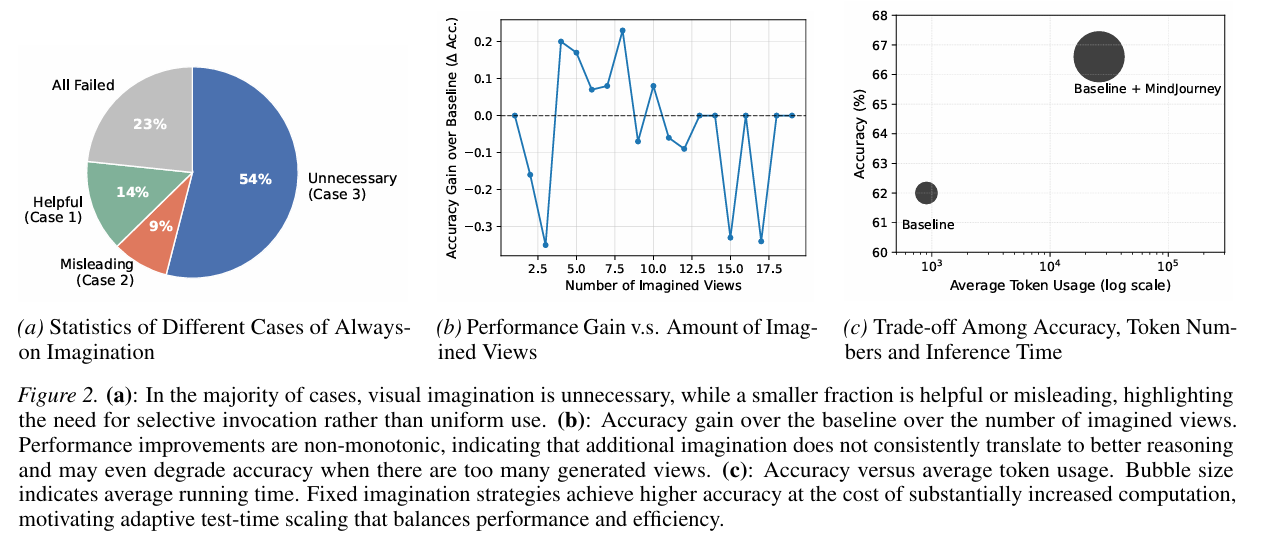
- 결과
- 분포
- case 3이 54% - 대부분의 경우 상상이 필요 없음
- 상상의 양 vs 성능
- 뷰를 많이 생성한다고 성능이 올라가지 않음
- 비용 vs 성능
- accuracy는 4.6% 증가하는데 토큰이나 추론 시간은 각각 100배, 30배씩 증가함
- 분포
- Selective imagination upper bound
필요할 때만 상상 사용하면 정확도는 75.3%임

⇒ 기존 always-on 방식이 비효율적이고 신뢰도도 낮음 - selective 방식의 필요성!!
Adaptive Imagination Control
- 관측 정보가 불완전한 상황에서 visual spatiol reasoning을 다룸
- 목표는 상상을 많이 쓰는 것이 아니라 언제, 얼마나 사용할지 결정하는 것
- 필요할 때만 월드 모델을 호출하는 adaptive test-time 프레임워크 AVIC를 제안함
- 4.1. 문제 정의
- 입력: 시각적 입력 I, 질문, 선택지
- 필요하면 월드 모델을 통해 action sequence에 따른 새로운 뷰를 생성할 수 있음
최종 답은

- 4.2. Gating
- policy 모델이 먼저 판단
- d ∈ {skip, call_wm}
- skip: 월드 모델 필요 없음
call_wm: action plan 생성
π = (u1, …, uT)
- 또는, 강건성을 위해
- policy를 여러번 샘플링
- majority voting으로 결정
- self-consistency 기반 gating
- 4.3. Action 실행 + trajectory 선택
- 월드모델 W로 액션 실행
- Iπ = W(I, π)
- trajectory 중에서 일부는 유용하지만 일부는 노이즈 o
이를 해결하기 위해 verifier V 사용
s(m) = V(I, q, Iπ(m)) π* = argmax s(m)
- 전체 trajectory 단위로 평가
- 4.3. 최종 답
â = argmax P(a I, Iπ*, q) - skip이면 I만 사용하고, 아니면 선택된 상상된 뷰 활용
Experiments
- rq 2개
- adaptive test-time scaling이 기존의 always-on 전략보다 공간 추론 성능을 향상시키는가?
- 높은 성능을 위해 실제로 얼마나 많은 상상이 필요한가?
- setup
- 데이터셋 및 벤치마크
- SAT, MMSI
- R2R
- 데이터셋 및 벤치마크
- 구현 세부사항
- 전체 시스템은 vlm과 사전학습된 월드모델을 기반으로 구축됨
- policy model, verifier, qa 모델은 **모두 같은 mllm을 사용**
- 모든 결정은 test time에서 수행되고 학습은 X
- action planning은 기본적으로 5번 샘플링해서 사용
- 평가
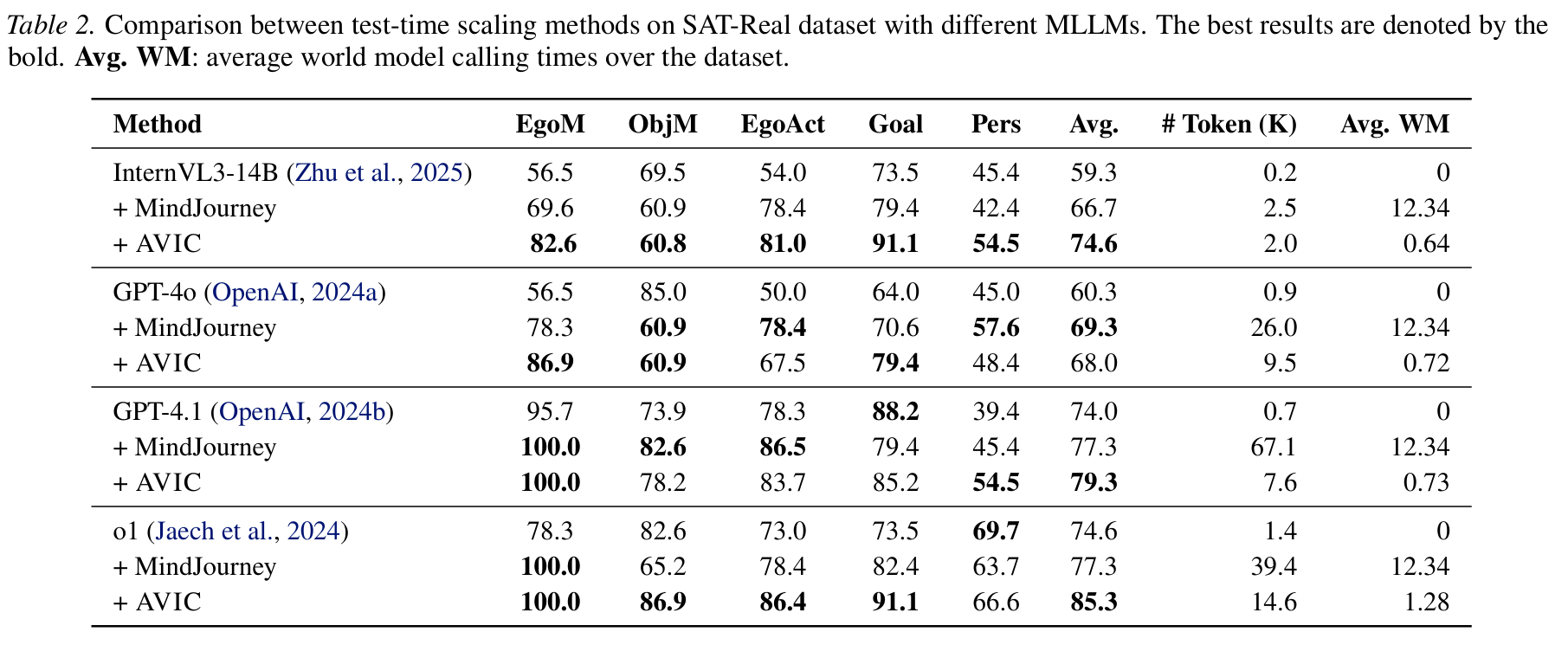
- SAT-Real 벤치마크에서 평가
- metric: 정확도 + 계산 비용 (토큰 수, 실행 시간)
- 모든 mllm에서 AVIC를 붙였더니 일관되게 성능향상
- always-on 방식인 mind journey에 비교해도 더 좋은 성능을 보임
- 특히 성능 향상은 다음 task에서 나타남
- egocentric movement
- action consequence
- perspective
→ 시점 변화나 행동 기반 추론이 필요한 문제에서 효과가 큼
- 효율성 측면에서도 큰 차이를 보임
- avic는 토큰이 약 10% 수준, 평균 실행시간 약 30초
- mindjourney에 비해 훨씬 효율적임
→ 무조건 상상을 늘리는 것보다 필요할 때만 사용하는 것이 더 효과적이고 효율적임!
- navigation task에서도 평가
mapGPT 위에 AVIC를 적용해서 비교함
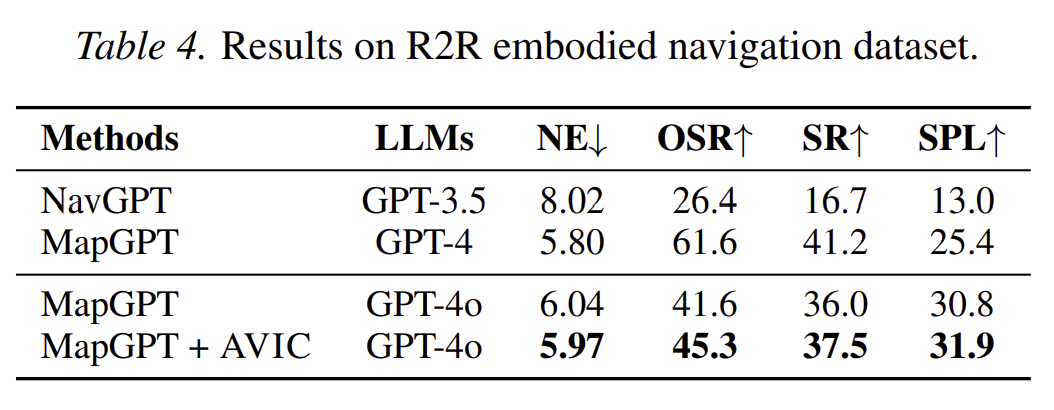
- 기존 방법 navGPT, MapGPT와 비교
- 동작 구조:
- 현재/과거 view → graph 구성
- policy가 추가 정보 필요 여부 판단
- 선택된 view 기반으로 imagined view 생성
- 합쳐진 view로 다음 action 결정
- 결과: 더 짧고 덜 불필요한 경로로 목표에 도달한다는 것을 뜻함
- 월드 모델 상상이 모호한 시각-공간 판단을 해결하는데 도움을 준다는 것을 보여줌
- 전반적으로 AVIC는 embodied navigation에서도 효과적으로 성능 향상
5.3. Ablation study
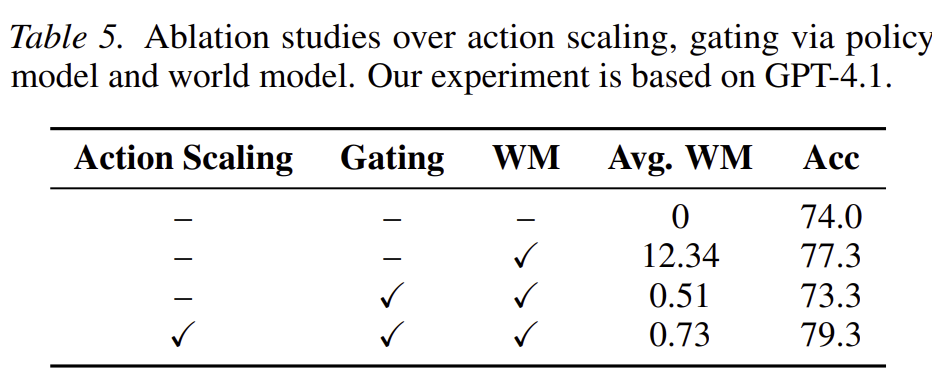
- WM만 사용하는 경우: always-on 방식
- 계속 월드모델을 호출하면 77.3
- avg. wm는 평균 월드모델 호출, 횟수가 커져 계산비용이 큼
- policy 모델을 사용해 gating을 적용하는 경우
- wm 호출 횟수가 크게 줄어들지만 정확도가 감소
- action level scaling까지 적용하면 wm 호출은 줄어들면서도 정확도는 가장 높음
→ wm을 언제 사용할지 (gating) 뿐 아니라 어떻게 사용할지 (action-level planning)이 모두 중요함
- WM만 사용하는 경우: always-on 방식
- 5.4. When and How much a world model is needed for visual spatial reasoning?
- visual spatial reasoning에서 월드 모델이 언제, 얼마나 필요한가?
- mllm의 실패 사례를 사람이 직접 분석해 4가지 에러 유형으로 나눔
- limited observability: 현재 시점에서 가려짐, 시야 제한으로 필요한 정보가 보이지 않는 경우
- viewpoint dependence: 관찰자 좌표계와 객체 좌표계 변환이 필요한 경우
- action-conditioned reasoning: 특정 행동 이후의 상태를 추론해야하는 경우
- dynamics understanding: 시간에 따른 변화를 이해해야하는 경우
- 이 에러들은 특정 task와 1:1 대응이 아니라 혼합적으로 나타남
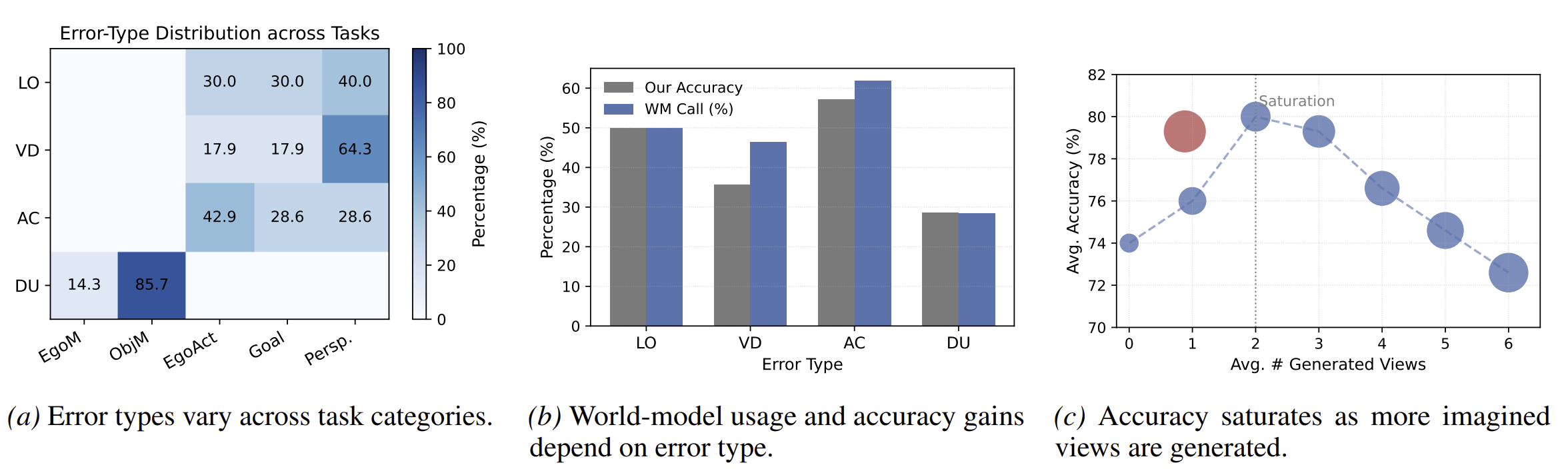
- RQ1: 언제 월드모델을 써야하는가
- _월드모델은 “행동 이후 상태를 예측해야할 때” 선택적으로 사용하는 것이 적절함_
- AC에서 가장 큰 성능 향상이 나타남
- 새로운 뷰를 생성해야 풀 수 있는 문제들
- RQ2: 얼마나 상상이 필요한가
- 많이 생성하는 것이 아니라 적게 생성하는 것이 효과적임
- 1~2개의 상상 view만 추가해도 정확도가 크게 오름
- 그 이상 생성하면 계산량만 증가하고 성능은 더 오르지 않거나 오히려 떨어짐
- 제안 방법은 평균 0.88개의 뷰만 사용하면서도 성능은 높음
- 고정적으로 많이 생성하는 방식보다 필요할 때만, 적게 생성하는 방식이 더 효율적임
정성적 평가

- 제안한 방법 vs always-on MindJourney
- 첫번째 예시: mindjourney는 굳이 상상이 필요 없는데도 호출해서 잘못된 정보가 생성되어 틀림
- 두번째 예시: mj는 무작위적으로 많은 뷰를 생성하지만 중요한 공간 조건을 제대로 반영 x 오답
- 밑의 navigation 예시
- 제안방법은 필요할 때만 월드모델 호출해서 유의미한 시각 정보를 선택적으로 추가함
- 상상을 안하는 베이스라인 모델은 충분한 시각 정보가 없어 잘못된 방향을 선택함
Conclusion
- 본 연구에서는 월드 모델을 활용한 visual spatial reasoning을 adaptive test-time scaling 관점에서 분석함
- 항상 상상을 수행하는 방식은 불필요하거나 오히려 성능을 떨어뜨릴 수 있음을 발견함
- 이를 해결하기 위해 AVIC를 제안 - 추론 시점에서 월드 모델을 언제 사용할지와 얼마나 상상을 수행할지를 선택적으로 결정함
- 여러 벤치마크에서 AVIC은 기존 방법 대비 비용을 줄이고 성능은 비슷하거나 더 좋은 성능을 달성함
- 분석 결과 월드 모델은 특히 행동 이후 상황 추론 케이스에서 가장 효과적이며, 일반적으로는 적은 상상만으로 충분하다는걸 확인함
- 효율적이고 신뢰성 있는 추론을 위해서 상황별로 다른 test-time scaling 전략이 중요함을 보여줌
This post is licensed under CC BY 4.0 by the author.