World2VLM: Distilling World Model Imagination into VLMs for Dynamic Spatial Reasoning
World2VLM: Distilling World Model Imagination into VLMs for Dynamic Spatial Reasoning
- 26.04 arxiv
- 코드: https://github.com/WanyueZhang-ai/World2VLM
- 데이터셋: https://huggingface.co/datasets/WanyueZhang/World2VLM
Abstract
- vlm은 정적인 장면 이해에서는 좋은 성능, 사람이 움직였을 때 장면이 어떻게 변하는지 이를 상상해야하는 동적 공간 추론에는 여전히 어려움을 겪음
- 최근 연구들은 두 갈래로 나뉘어짐
- 합성 데이터 기반 spatial supervision을 대규모로 학습
- 행동에 따라 공간 상태가 어떻게 변하는지 명시적으로 모델링하지 못하는 경우가 많음
- 추론 시점에 VLM과 월드 모델을 결합하는 방식
- 추론 과정에서 큰 연산 비용이 들음
- 합성 데이터 기반 spatial supervision을 대규모로 학습
- 본 연구는 이를 해결하기 위해 World2VLM이라는 **학습 프레임워크**를 제시
- 생성형 월드 모델이 가진 공간 상상 능력을 vlm에 distillation하는 것
- 초기 관측 이미지와 카메라 이동 경로가 주어지면 월드 모델을 사용해서 미래 시점을 상상함
- 이를 기반으로 forward/inverse spatial reasoning을 수행하기 위한 구조화된 supervision을 구축함
- 이렇게 생성한 데이터셋으로 2-stage 방식의 post-traning을 수행함
- 실험 결과 SAT, VSI-Bench, MindCube 등 여러 spatial reasoning benchmark에서 기존 베이스모델보다 일관된 성능 향상을 보임
- 추론 시점에서 월드 모델을 직접 붙여 쓰는 방식보다도 더 좋은 성능을 내면서, 비싼 생성 비용은 제거함
- **→ 월드 모델이 단순히 추론시점에서 호출하는 툴이 아니라, 공간 상상 능력을 vlm에 내재화하도록 가르치는 training-time teacher 역할도 할 수 있음을 보여줌**
Introduction
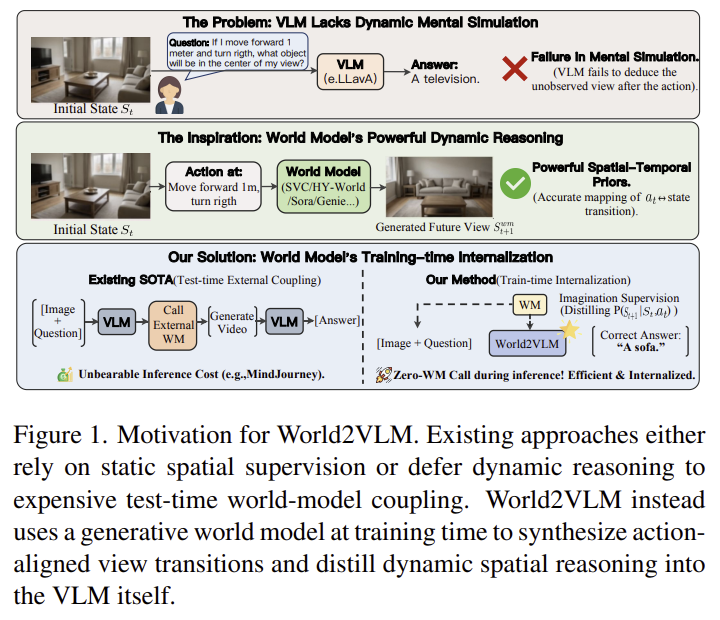
- VLM의 공간 이해 능력의 필요성
- 현재 VLM의 한계
- 사용자가 움직였을 때 장면이 어떻게 변하는지 추론
- 행동의 결과를 예측
- 보이지 않는 시점을 머릿속으로 상상
- 이는 다음과 같은 task에서 두드러짐
- 시점 변화
- multi-step transformation
- action-conditioned reasoning
- 현재 모델들은 진짜 공간 이해보다는 shallow pattern matching에 의존하는 경향이 있음
- ego-centric 멀티뷰 연구들도 camera motion 자체가 여전히 핵심 병목임을 보여줌
- 기존 해결방법
- 합성 spatial supervision 확장
- 시뮬레이션 / 합성 데이터 / 벤치마크 확장
- 하지만 대부분 정적인 supervision만 제공
- 행동에 따라 관측이 어떻게 변하는지를 명시적으로 모델링하지 않음
- 추론 시점 월드 모델 coupling
- 추론 시점에 월드모델을 사용해서 상상 기반의 추론을 하게끔함
- 매우 비싸고 느림
- vlm은 변하지 않음 - RQ: 월드 모델을 추론 툴이 아니라 학습할 때 teacher로 사용할 수 있을까?
- 합성 spatial supervision 확장
- 본 연구는 world2VLM을 제안함
- world model로 미래 view 생성
- 이를 supervision으로 변환
- spatial imagination 능력을 VLM 내부에 distill
Related work
- Spatial Reasoning in VLMs
- vlm의 핵심 약점 중 하나가 공간 추론이라는 점이 많은 연구에서 밝혀지고 있음
- 기존 벤치마크: SAT, VSI-Bench, MindCube, 3DSRBench, SITE
- 단일 이미지 기반 테스트뿐 아니라, 멀티모달 종합 평가, 멀티뷰 환경, 그리고 시점 변화나 동적 환경을 포함하는 다양한 상황
- 특히 camera-centric이나 ego-centric 관점에서 진행된 multiview 분석들은 강력한 최신 mllm도 **시점 변화나 카메라 제어를 제대로 이해하지 못한다는 점을 보여줌**
- 학습 측면에서의 시도들
- 3d 데이터 활용
- 동적 aptitude task
- synthetic spatial vqa
- single-view에서 비디오 형태의 커리큘럼 학습
- _“공간 reasoning은 그냥 instruction tuning만으로 안 되고, spatial experience 자체가 필요하다”_
- 최근 post-training 방식들
- viewpoint-consistent learning
- progressive curriculum
- explicit 3D representation
- camera-motion reasoning
- visual intermediate reasoning
- spatial-aware architecture
- _“생각 과정 자체를 spatial-aware하게 만들자.”_
- 또 다른 공간 추론 실패를 극복하고자 한 시도들 - explicit reasoning 방법
- Video-of-Thought
- imagination prompting
- SpatialCoT
- grounded CoT
- allocentric trace
- explicit 3D exploration
- _모델이 “머릿속 시뮬레이션”_
- 본 연구는 단순히 cot 생성이 아니라 행동 이후 상태 변화 자체를 supervision으로 사용함
- spatial reasoning을 language reasoning 문제가 아니라 transition modeling 문제로 본다는 것
- World Models for Spatial Dynamics
- 본 연구에서는 조건으로 이미지, 카메라 정보, 비디오 문맥 등을 받아 미래 관측을 생성하는 생성형 월드 모델을 사용함
- genie, sora, hunyuanVideo 등 interactive/video model
- GEN3C 등 controllable 생성 모델의 발전
- 이런 형태의 supervision을 실제 학습에 사용하는 것이 현실화되고 있음
- svc는 camera-conditioned novel view 생성에 특화
- HY-WorldPlay는 action-conditioned long-horizon dynamics에 포커스
- 본 연구는 이런 월드 모델들을 추론 생성기로 활용하는 것이 아니라 학습할 때 teacher로 사용함
- 본 연구에서는 조건으로 이미지, 카메라 정보, 비디오 문맥 등을 받아 미래 관측을 생성하는 생성형 월드 모델을 사용함
- Mental Simulation with World Models
- vlm이 상상된 시점이나 내부 spatial representation을 통해 추론할 수 있는지를 탐구함
- Mindjourney
- inference 단계에서 controllable world model과 vlm을 결합하여 모델이 상상된 view를 반복적으로 생성하고 이를 기반으로 추론할 수 있게 만듦
- 이 과정은 finetuning x
- SpatialDreamer
- 강화학습과 geometry-aware optimization을 추가해서 world-model 기반 상상을 더욱 강화시킴
- 이런 방법들은 추론 단계에서 월드 모델을 결합하면 spatial reasoning 성능이 향상될 수 있음을 보여줌
- 하지만 한계점으로는
- **높은 추론 비용**
- **외부 월드 모델 의존성**
- **vlm은 변화 x**
- MindCube
- 제한된 시점 정보만으로 spatial mental modeling을 수행하는 문제를 다룸
- intermediate cognitive map을 명시적으로 구성하면 perspective tracking과 mental simulation 능력이 향상됨을 보여줌
- 이 연구들은 “상상된 중간 구조”의 중요성을 보여줌
- 본 연구는 월드 모델을 추론 시점이 아니라 학습 시점으로 옮김
- 생성된 미래 관측을 supervision으로 사용하고, action-conditioned transition 자체를 vlm 내부에 직접 학습시킴
Method
💡 “World Model이 생성한 시점 변화 데이터를 이용해, VLM 내부에 spatial transition dynamics를 학습시킨다.”
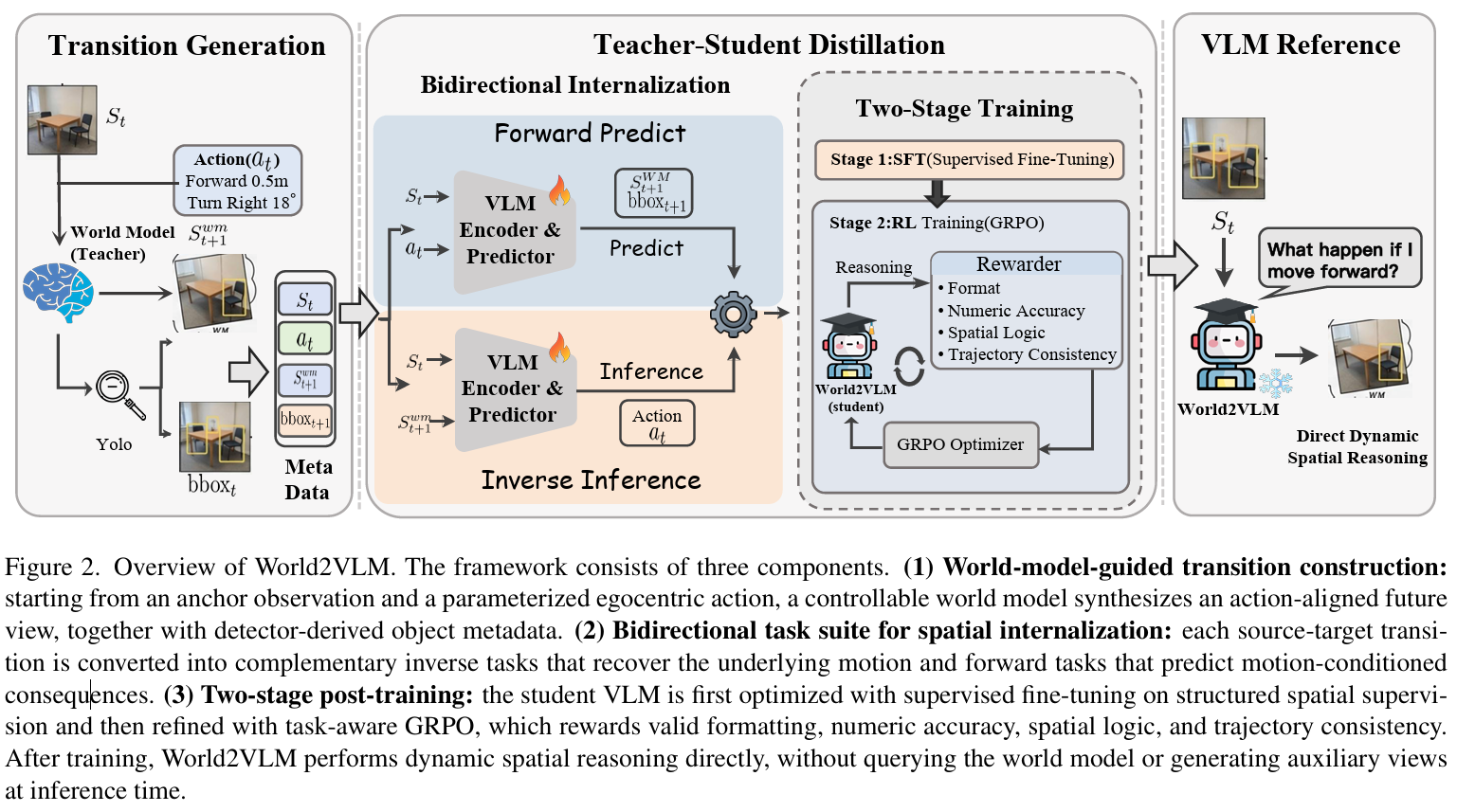
- 전체 구조
- teacher: SVC, HYWorldPlay, 기타 controllable world model
- student: 최종 vlm
- 3.1. Overview
핵심 수식
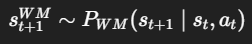
- 입력: 이미지 s_t, 카메라 이동 a_t
- 출력: s_t+1 (미래 view)
- action-conditioned future prediction을 생성함
VLM이 학습하는 것
Inverse reasoning

- 연속된 시점의 두 이미지를 보고 “무슨 행동이 있었는지” 추론
Forward reasoning

- 현재 시점의 뷰에서 어떤 행동을 했을 때 “앞으로 어떤 변화가 생길까?” 예측
- 3.2. Transition Construction
- Trajectory-conditioned synthesis
- 현재 시점의 이미지에서 action trajectory를 샘플링함
- rotate, move, multi-step motion
- 이에 맞춰 월드 모델이 미래 이미지를 생성해서
- 상상된 trajectory rollout을 만듦
- 현재 시점의 이미지에서 action trajectory를 샘플링함
- Max-Displacement Pairing
- 가까운 프레임끼리 쓰는게 아니라 **가장 멀리 변화한 프레임을 사용**함
- 왜냐면 짧은 변화는 모델이 맞추기에 쉬우니까 → 쉬운 shortcut 방지
- 큰 변화여야지 실제 공간추론을 할 수 있게 됨
- Spatial Anchoring
- object box를 이미지에 그리지 않고 텍스트 프롬프트에 넣음
- 이미지에 넣으면 visual shortcut이 생기고 detector artifact에 의존할 수 있음
- Trajectory-conditioned synthesis
- 3.3. Task Suite
- 8개의 task를 학습함
- **Inverse Tasks**
- 결과 뷰를 보고 무슨 motion이 있었는지 예측
- ex.
- rotation angle
- move distance
- multi-step action recovery
- Observation → Action
- **Forward Tasks**
- 현재 상태와 행동을 보고 어떤 결과가 생기는지 예측
- ex.
- object localization
- visibility prediction
- identity consistency
- Action → Consequence
- 이렇게 forward/inverse 양방향을 동시에 해야 진정한 공간 representation이 생김
- inverse만 하면: 패턴 matching shortcut이 가능
- forward만 하면: language prior shortcut 가능
- 3.4. Stage 1: SFT Distillation
loss
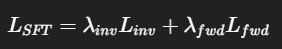
- inverse + forward supervision joint training
같은 transition을 반대방향에서 봄으로써 양방향 consistency 강제함
- 3.5. Stage 2: GRPO Refinement
- SFT 후 RL refinement
reward를 spatial-aware하게 설계함
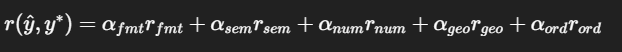
- format
- 답 형식 맞는가
- semantic
- 정답 맞는가
- numeric
- 거리/각도 정확한가
- geometry
- bbox localization 정확한가
- order
- multi-step sequence 논리 맞는가
- format
- GRPO 목표
- 좋은 spatial reasoning output 강화
- SFT policy에서 너무 멀어지는 것 방지
Experiments
- Experimental setup
- baseline model
- qwen2.5-vl-7b
- teacher world models
- SVC
- 카메라 조건 기반 시점 생성에 특화
- HY-WorldPlay
- action-conditioned world model / video-generation prior를 제공함
- SVC
- 학습 데이터
- 실제 실내 장면 ScanNet
- 시뮬레이션 환경 MulSeT
- anchor observation과 ego-centric action을 기반으로 월드 모델이 미래 시점 생성
- 8개 task로 변환함 - SFT 데이터는 약 100K, GRPO는 1K balanced subset으로 구성됨
- 평가
- SAT-Real, SAT-Synthesized, VSI-Bench, MindCube
- 베이스라인
- 기본 qwen2.5-7b
- 추론 단계에서 월드 모델 호출하는 베이스라인
- test-time coupling baseline은 mindjourney 스타일 search-and-score 파이프라인을 기반으로 구현함
- 월드 모델이 후보 action에 대한 상상된 view 생성
- vlm이 각 후보를 scoring
- 가장 적절한 trajectory 선택 후 답 생성
- test-time coupling baseline은 mindjourney 스타일 search-and-score 파이프라인을 기반으로 구현함
- 월드 모델 supervision을 제거하거나 약화한 controlled data baseline
- world2vlm-sft, world2vlm-grpo
- Training Recipe
- lora 기반 peft 방법 사용
- 월드 모델은 offline data 생성할 때만 사용되고 추론할 때는 사용 x
- 벤치마크 데이터로 학습 절대 안했음 강조함, 월드 모델이 생성한 데이터로만 학습
- baseline model
Overall Results
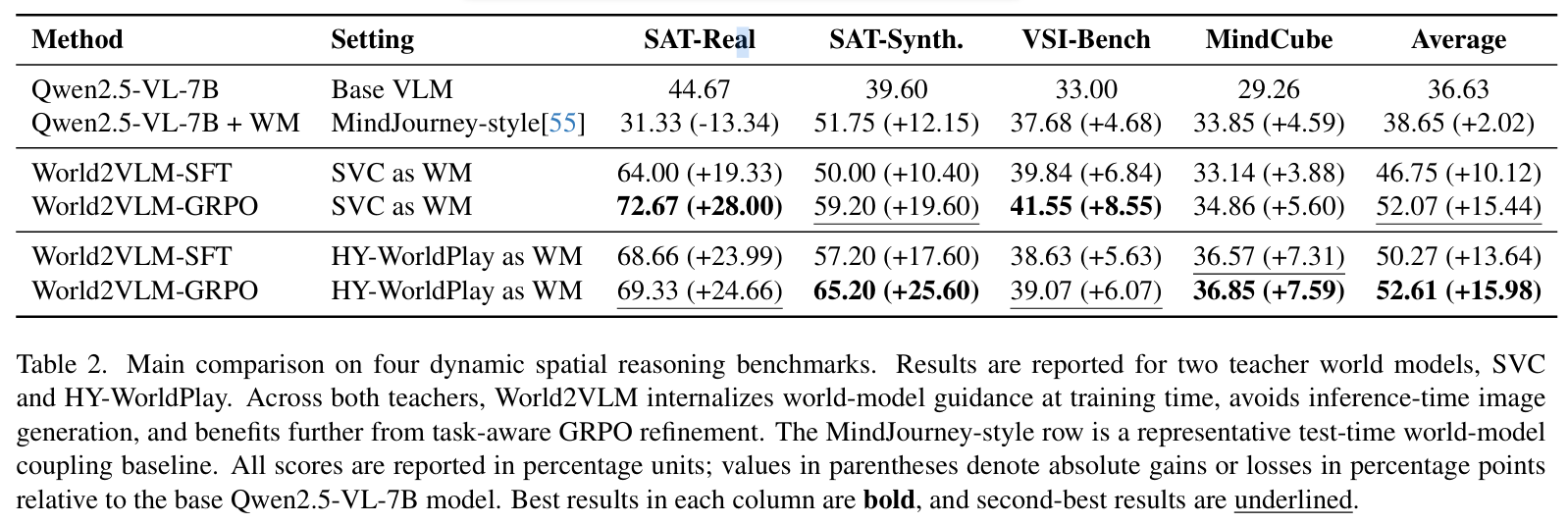
- 본 연구에서 사용한 학습 시 월드 모델을 내재화 하는 방법이 teacher world 모델 2개 모두에서 test-time coupling보다 더 성능이 좋았음
- SVC를 teacher로 사용할 경우
- sat-real, vsi-bench에서 가장 높은 성능을 보임
- camera-conditioned 뷰포인트 일관성이 중요한 벤치마크에서 강함
- HY-WorldPlay를 teacher로 사용할 경우
- sat-synthesized, mindcube, overall에서 좋은 성능을 보임
- action-conditioned temporal prior가 더 유리한 벤치마크에서 좋은 성
world2vlm이 특정 generator family에만 의존하지 않고, 서로 다른 world-model prior에서도 일반적으로 동작함을 시사함
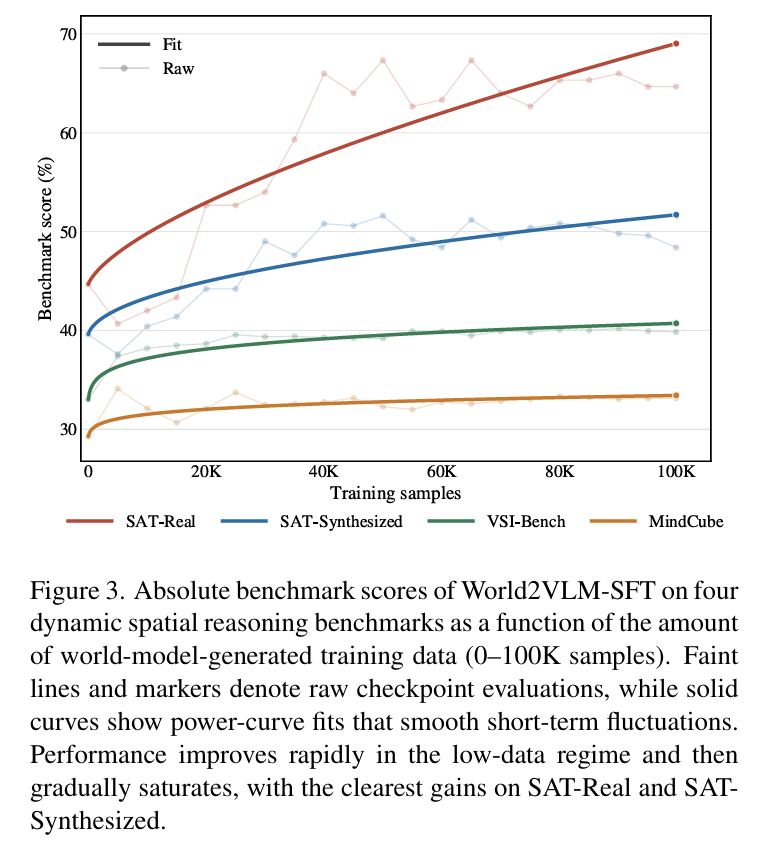
- 월드 모델이 생성한 sft 데이터를 0에서 100k까지 늘렸을 때 성능 변화
- raw 점수는 일정하게 증가하는건 아니고 약간 출렁거림
- power-fit curve는 이를 추세선으로 근사한 것
- raw point는 noisy하니까 underlying trend를 보기 위해 smooth curve를 피팅한 것
- 전체적인 증가 경향을 보기 위함
- SAT-r/s에서 모두 효과가 크게 나타남
- 이 데이터셋들이 motion-conditioned viewpoint reasoninng에 더 직접적으로 의존하기 때문
- SAT-real breakdown
- ego-centric motion 상황에서의 dynamic spatial reasoning을 세부 task로 분해해서 평가
- egocentric movement → 카메라 이동 이후 scene을 업데이트해야 하는 task
- object movement → object가 view 사이에서 어떻게 이동했는지 추적하는 task
- goal aim → 특정 target이 action 이후 reachable/visible 해지는지 판단하는 task
- action consequence → action 이후 spatial relation이 어떻게 바뀌는지 예측하는 task
perspective taking → 다른 agent의 시점에서 reasoning하는 task
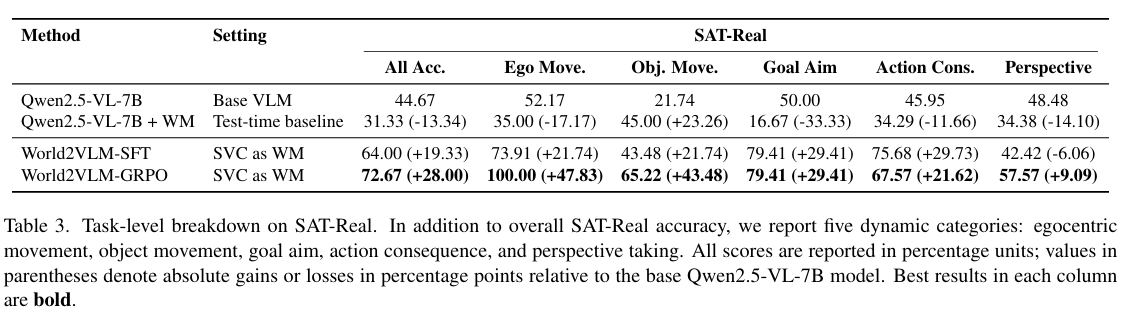
- 결과를 보면 특정 task에서 성능 향상이 나타난 것이 아니라 여러 카테고리에 걸쳐서 나타남
- 특히 sft 단계만으로도 대부분 카테고리에서 성능 향상
- perspective taking은 오히려 성능 저하
- grpo 이후에는 개선이 더욱 커짐
- perspective taking은 단순 transition supervision만이 아니라, 더욱 정교하게 calibrated된 rl refinement의 도움도 필요하기 때문
- action consequence는 rl보다는 sft distillation만으로 충분히 내재화되기 쉬운 task라는 의미
- mindjourney 방식은 어떤 taks는 도움이 되지만 어떤 task는 도움이 안됨
- unstable함
- 반면 world2vlm은 파라미터 내부에 내재화되어 있으므로 더욱 안정적인 추론 가능
- Ablation Study
- 양방향 학습의 효과
- forward와 inverse distillation이 서로 보완적인가? or 둘 중 하나로도 충분한가?
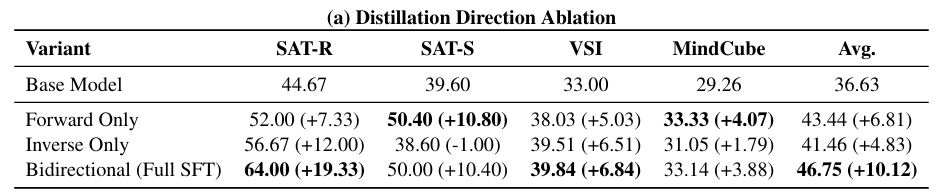
- forward only랑 inverse only는 각각 잘하는 벤치마크가 다름
- 두 방향을 함께 사용했을 때 가장 높은 성능이 나옴
- 양방향 학습은 단순히 task 다양화를 하는 것이 아니라,
- 동일한 transition에 대해서 explanation과 prediction, 즉 양쪽 constraint를 모두 거는 것임
- → 설명과 예측 둘 다 가능한 spatial representation을 학습하게 만듦
- 학습 소스의 효과
real scene과 합성 데이터 중 무엇이 더 중요한가?
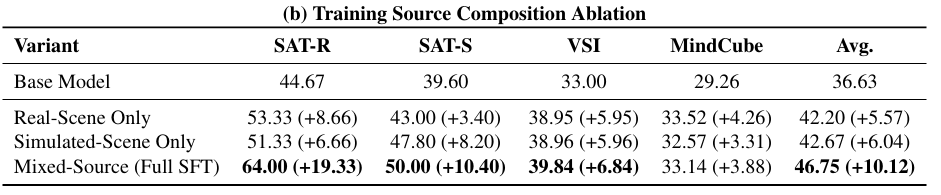
- real scene으로 학습하면 sat-r에서 더 강하고, 합성 데이터로 학습하면 sat-s에서 더 강함
- 하지만 둘을 모두 학습한 결과가 성능이 가장 좋음
- → 두 도메인이 서로 보완적인 supervision을 제공하기 때문
- → 둘을 함께 사용하면, real / synthetic 양쪽 환경 모두에서 robust한 spatial transition prior를 학습하게 된다
- 양방향 학습의 효과
Conclusion
- 본 연구는 world2vlm이라는 학습 프레임워크를 제안함
- 핵심 아이디어: **월드 모델이 생성한 view transition을 dynamic spatial reasoning의 supervision으로 사용하는 것**
- 학습 시 inverse + forward spatial reasoning을 결합
- sft + grpo의 2단계 학습 수행
- vlm은 추론 시 상상을 호출하지 않고도 ego-centric action에 따라 scene이 어떻게 변화하는지를 내부적으로 학습하게 됨
- 월드 모델을 추론할 때 사용하는 것이 아니라, 학습할때 teacher로 사용
- motion-conditioned view는 motion 추론, action 연속 예측을 학습하기 위한 supervision으로 동작하게 됨
- 이후 grpo에서는 이미 모델 내부에 distill된 transition knowledge를 기반으로 structured spatial output을 더 정교하게 다듬음
- 실험 결과
- 여러 벤치마크에서 베이스라인 qwen2.5보다 성능 향상
- 특히 motion-conditioned reasoning에서 향상
- svc, hy-worldplay 등 서로 다른 teacher family 모두에 대해 잘 동작함
- mindjourney 스타일의 test-time coupling baseline보다 더 좋은 성능을 보임
- 추론 시에는 일반적인 vlm 추론만 함
- 여러 벤치마크에서 베이스라인 qwen2.5보다 성능 향상
- “world model을 training-time teacher로 사용하는 것이, VLM에 dynamic spatial reasoning 능력을 학습시키는 효과적이고 practical한 방법이다”
This post is licensed under CC BY 4.0 by the author.