SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities
SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities
- google, mit
Abstract

- 공간적 관계를 이해하고 추론하는 능력은 vqa와 로보틱스에서 핵심적인 역량
- VLM은 일부 VQA 벤치마크에서 뛰어난 성능
- 거리와 크기 차이와 같은 **물리적 객체 간의 정량적 관계를 이해하는 3D 공간 추론 능력**은 여전히 부족함
- 본 연구는 이 문제가 데이터 부족에서 기인한다고 가정 → **학습 데이터에 3D 공간 정보가 부족**하기 때문
- 인터넷 규모의 공간 추론 데이터를 활용해 이를 해결하고자 함
- 본 연구에서는 이를 위해 대규모 학습을 가능하게 하는 시스템을 제안함
- 실제 이미지 천만장을 기반으로 최대 20억 개의 VQA 데이터를 생성할 수 있는 **자동화된 3D 공간 VQA** **데이터 생성** **프레임워크**를 개발
- 이후 데이터 품질, 학습 파이프라인, 모델 구조 등 다양한 학습 요소들이 성능에 미치는 영향을 분석함
- 핵심 기여: metric space 기반의 인터넷 규모 3d 공간 추론 데이터셋을 최초로 구축한 것
- 이 데이터로 vlm을 학습했더니 정성적/정량적 공간 vqa 모두에서 성능이 크게 향상
- 이런 모델이 정량적 추정 능력을 기반으로 cot 기반 공간 추론과 로보틱스 응용 등 새로운 downstream task 가능성을 열 수 있음을 보임
Introduction
- VLM은 여러 task에서 큰 발전을 이뤘지만, 공간 추론 task에서는 한계를 보임
- ex. 3d 공간에서 객체의 위치나 객체 간 관계를 이해하는 작업 등
- 여러 다운스트림 응용에서 필수적임
- 공간 추론이 가능한 vlm은 더 나은 보상 평가기나 성공 판단기로 활용될 수 있음
- 인간은 신체 경험과 진화를 통해 선천적인 공간 추론 능력을 갖추고 있음
- vlm은 이런 능력이 부족해 여러 단계의 공간 추론이 필요한 실제 문제를 해결하기 어려움
- “vlm에 인간 수준의 공간 추론 능력을 부여할 수 있는가?”
- vlm은 이런 능력이 부족해 여러 단계의 공간 추론이 필요한 실제 문제를 해결하기 어려움
- 본 연구는 이 원인이 학습 데이터의 한계 때문이라고 가정
- 주로 학습하는 이미지-캡션 pair 데이터에 공간 정보가 부족하기 때문
- 3d 정보를 포함한 데이터나 고품질 주석을 얻기 어렵기 때문
- 자동 데이터 생성으로 이를 해결하고자 함
- 기존 포토리얼리스틱한 접근보다는, **실제 이미지에서 직접 공간 정보를 추출하는 방식으로 현실 세계의 복잡성을 반영하고자 함**
- 핵심 아이디어는 - 최신 비전 모델을 활용하면 2d 이미지로부터 3d 공간 정보를 자동으로 생성할 수 있다는 점
- spatialVLM: open-vocab 객체 탐지, metric depth 추정, semantic segmentation, 객체 중심 캡셔닝을 결합하여 대규모 실제 이미지에 대해서 밀도 높은 3d 주석을 생성함
- 이렇게 생성된 데이터는 캡셔닝, vqa, 공간 추론 데이터가 혼합된 형태로 변환되어 vlm 학습에 사용됨
- 이를 통해 모델은 3d 세계에 대한 지각적 기반을 학습하고, llm과 결합해 공간 추론을 수행함
- 효과
- 정성적으로 공간에 대한 성능 향상, 노이즈가 잇는 데이터에 대해서도 정량적 추정이 가능 …
- 기여
- vlm에 정량적 공간 추론 능력 부영
- 실제 이미지 기반 인터넷 규모 3d 공간 vqa 데이터 자동 생성 프레임워크 제안
- 데이터 품질, 학습 방식, 비전 인코더 freeze 여부 등 학습 전략 분석
- 복잡한 추론 및 로보틱스 응용에서 새로운 가능성 제시
Related work
- spatial reasoning
- slam이나 depth 추정과 같은 전통적인 문제들
- 장면 메모리, 장면 그래프
- vlm은 공간 정보를 암묵적으로 학습함
- 본 연구는 장면 그래프 없이 vlm 내부에서 직접 공간 관계를 학습
- 더 나아가 정성적 관계와 정량적 거리까지 다룸
- vlm의 grounding 문제
- grounding 부족 문제: 사회적 추론, 물리 추론, 공간 추론 ..
- 이를 해결하기 위해 vision-grounded 모델이 등장함
- 본 연구는 별도의 구조 추가 없이 vqa 데이터로 vlm을 finetuning함
- 기존 vlm의 일반성과 추론 능력을 유지하면서 공간 추론 + 보상 예측 같은 작업을 가능하게 함
- 기존 데이터셋의 한계
- 보통 vqav2, coco, visual genome
- segmentation, object detection 등 fine grained 이해에 집중
- 공간 추론 데이터가 존재하긴 하지만, **실제 데이터는 사람의 라벨링 한계가 있고, 합성 데이터는 표현력이 제한됨**
- 결과적으로 대규모 + 현실적 + 풍부한 3d 정보 데이터가 부족
SpatialVLM
- vlm에 공간 추론 능력을 부여하기 위해, 대규모 공간 vqa 데이터셋을 생성하고 이를 기반으로 모델을 학습함
- 데이터 생성 프레임워크 설계 - 기존 비전 task 사용해서 객체 중심 정보를 구성
- vqa 데이터 생성 - 템플릿 기반
- vlm 학습
- llm과 결합
3.1. Spatial Grounding from 2D Images
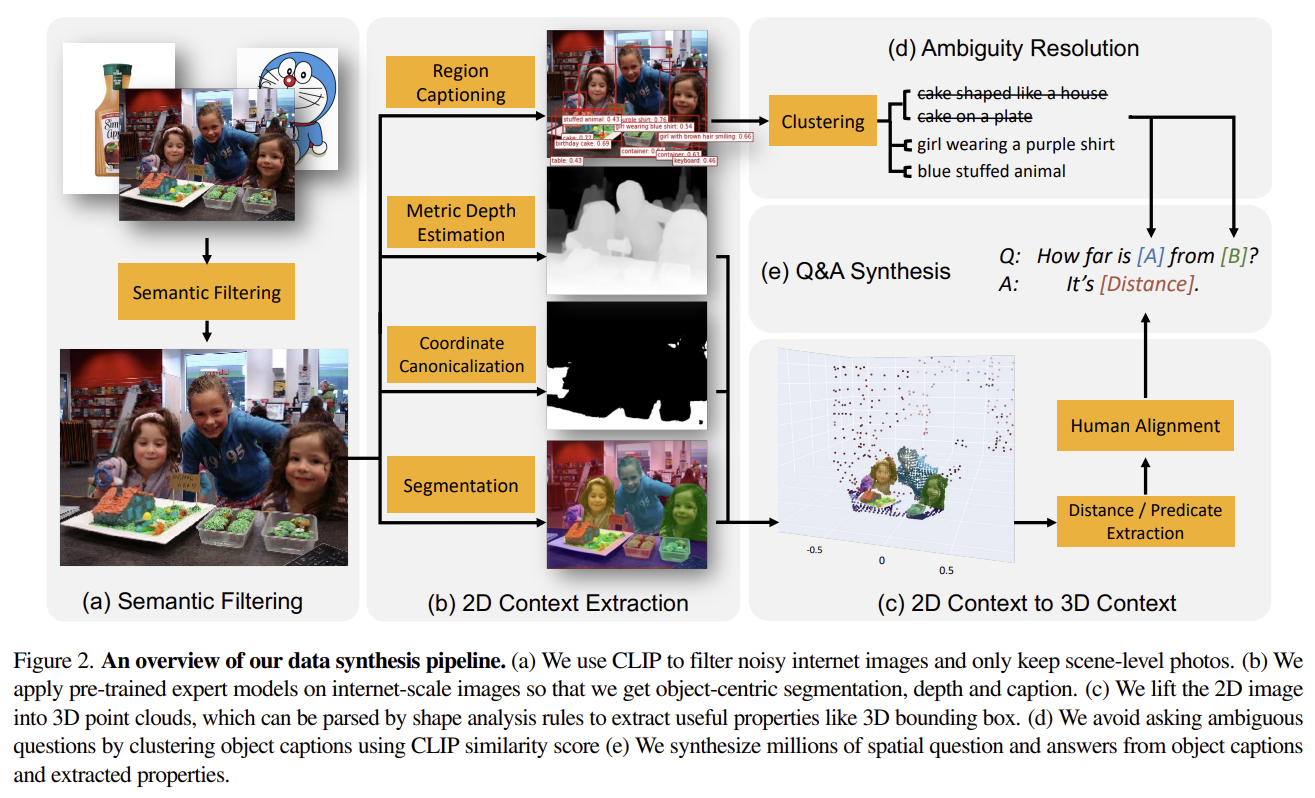
- Semantic filtering
- 인터넷 이미지 중 많은 데이터는 공간 추론 task에 적합하지 않음
- clip 기반 open-vocab 분류기로 공간 추론에 적합한 이미지만 선별
- Object-centric contexts extraction from images
- 이미지에서 객체 중심 정보를 추출하기 위해,
- region proposal, region captioning, semantic segmentation
- 객체 단위 픽셀 영역, 해당 객체의 텍스트 설명
- 객체 단위의 representation 확보
- 이미지에서 객체 중심 정보를 추출하기 위해,
- Lifting 2D contexts to 3D contexts
- 기존 이미지에는 거리/크기와 같은 metric 정보가 없음
- depth estimation으로 2d → 3d point cloud로 변환
- 좌표계를 실제 세계 기준으로 정렬
- 객체 간 실제 거리/크기 정보 포함된 3d 구조 생성
- object 중심의 3d point cloud 생성해서 vqa 데이터에 활용했다는 것이 큰 기여
- Ambiguity 해결
- 같은 클래스 객체가 여러개 있을때 모호해짐
- 더 세밀한 캡셔닝 사용
- flexcap 사용
- 한 객체에 대해서 길이 1~6의 단어를 랜덤하게 캡셔닝하도록 함
- 후처리로 모호성 제거
3.2. Large-Scale Spatial Reasoning VQA Dataset
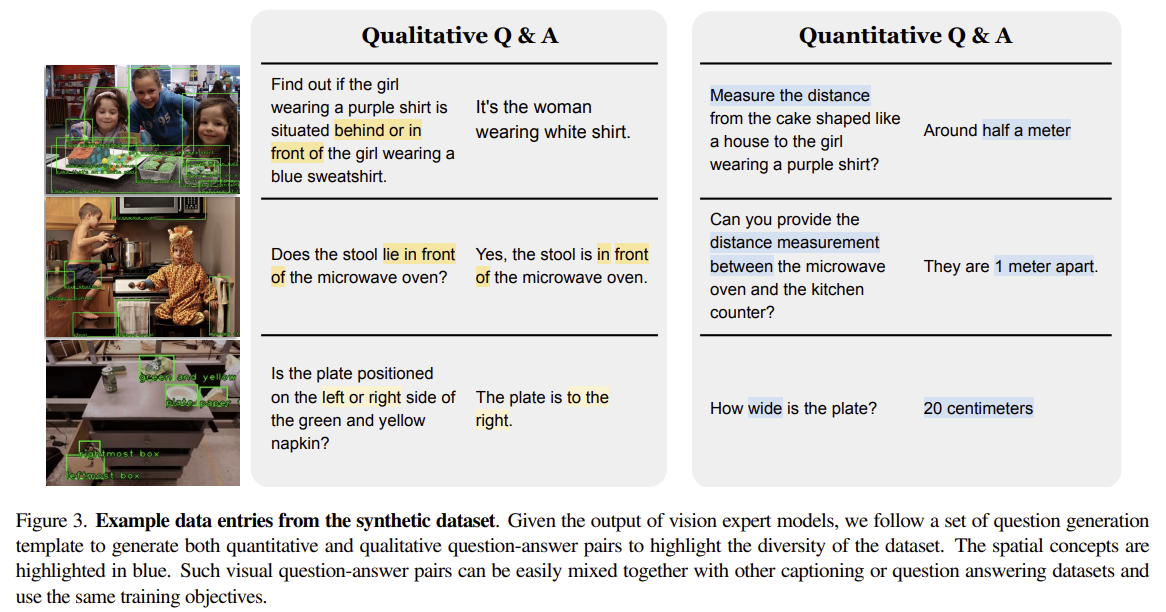
- vlm에 직관적인 공간 추론 능력을 학습시키기 위해 합성 데이터를 사용해 사전학습 수행
- 문제 설정: 단순하게 이미지 내 두 객체 a, b만 고려
- 복잡도 줄이고 학습 안정화
- 질문 유형
- 정성적 질문
- 관계 판단 중심 - 비교 / 방향 / 상대적 관계
- a와 b중 더 왼쪽에 있는것, 더 위에 있는 것, 더 넓은 것
- 정량적 질문
- 숫자 기반 추론 - 거리, 위치, 차이, 단위
- a와 b 사이 거리, 얼마나 뒤에 있는지 등
- 정성적 질문
- 데이터 생성 방식
- 템플릿 기반 생성
- 객체 이름은 구체적인 캡션을 사용해서 이름 붙
- **정답은 3d point cloud, 3d bounding box 기반 함수로 계산**
- 데이터 구성
- 총 38개 질문 유형 - 20개 질문, 10개 답변 템플릿
- 이미지: 1000만장, qa 쌍 20억개
- 정성적 50%, 정량적 50%
3.3. Learning Spatial Reasoning
- Direct spatial reasoning
- 입력: 이미지 + 공간에 대한 질문
- 출력: 답변
- 외부 도구 없이 vlm이 혼자 바로 답함
- 텍스트로 바로 답함
- palm-e 구조를 거의 그대로 쓰고, backbone만 더 작은 palm 2-s로 바꿈
- 원래 palm-e 데이터 + 본 논문에서 구축한 spatial 데이터 섞어서 학습함 (finetuning)
- 전체 토큰 중 5% 정도를 spatial task에 사용함
- 이 모델은 기존 모델처럼 일반 vqa도 하고 공간 추론 질문도 잘하게 됨
Chain of thought spatial reasoning

- 한 번에 못 풀고 중간 단계가 필요한 여러 단계 reasoning이 필요한 문제들
- spatialVLM이 기초 공간 질문에 답하면, 강력한 llm이 복잡한 질문에 대답하는 구조
- “이 상자에 저 물건이 들어가?”
- LLM이 내부적으로
- 물건 폭은?
- 상자 입구 폭은?
- 물건 높이는?
- 상자 높이는?
- 비교해서 결론 내리기
이렇게 작은 질문들로 분해하고, 각 질문을 SpatialVLM에 물어본 뒤, 답을 모아서 최종 결론을 냄
⇒ Chain-of-thought Spatial Reasoning
- 이 연구는 복잡한 multi-hop 문제를 직접 학습시키기보다는 직접적인 spatial QA만 학습시킴
Experiments
- RQ
- 본 연구에서 구축한 spatial VQA 데이터 생성 및 학습 파이프라인이 vlm의 전반적인 공간 추론 능력을 향상시키는지? 성능은 어느정도인지?
- 노이즈가 있는 합성 spatial VQA 데이터와 다양한 학습 전략이 성능에 어떤 영향을 미치는지?
- 직접적인 공간 추론 능력을 갖춘 vlm이 cot 추론이나 embodied planning 같은 새로운 능력을 가능하게 하는가?
- 모델은 palm-e training set과 자체 spatial vqa 데이터를 혼합해 학습함
- 공간 추론 한계가 데이터 문제때문인지 확인하기 위해 semantic captioning 비중이 높은 데이터로 학습된 sota vlm을 베이스라인으로 사용함
- 비교 모델
- gpt-4v, PaLI, PaLM-E, PaLM 2-E, llava-1.5, instructblip
- 4.1. Spatial VQA 성능
- vlm의 공간 추론 능력을 제대로 평가하기 위한 spatial VQA 벤치마크가 없음
- 직접 구축
- WebLI 이미지 일부 사용 (학습 X)
- 사람이 직접 정량적 정성적 질문/답변 생성
- 정성적: 331개
- 정량적: 215개
- 3.2. 합성 데이터 생성 방식으로 생성함
- 정성적 분석
- 정답과 모델 출력이 자연어라서 자동 평가 어려움
- 사람 평가자가 직접 평가함 : 정확도로 평가함
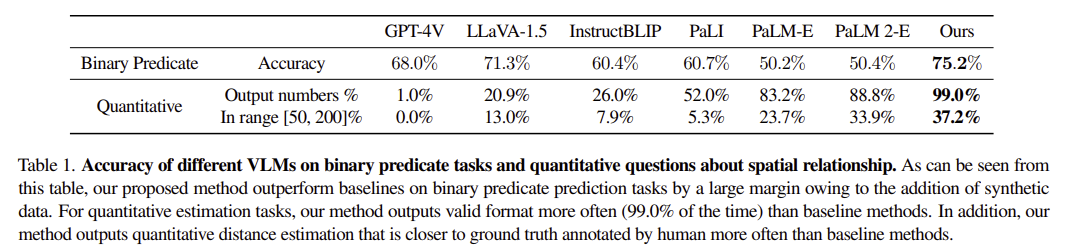
- Spatial vlm이 모든 베이스라인 대비 최고 성능, 특히 gpt-4v보다 성능 우수함
- 베이스라인 중 최고는 llava 1.5 - bbox + caption 기반 instruction tuning 영향으로 추정
- llava 1.5는 2d 공간 추론은 잘하는데 3d 공간 추론에는 약함
- → 대용량 + 고품질 공간 추론 데이터가 공간 추론 능력에 핵심임
- 정량적 분석
- vlm 평가를 위한 2가지 메트릭 설계
- **vlm이 숫자를 생성하는 성공률**
- 정량적 공간 추론 질문을 이해했는가
- **답의 기준 범위 분포가 다양하기 때문에, 답이 실제 값의 0.5~2배 범위에 들어가는 비율로 정확도를 평가**
- **vlm이 숫자를 생성하는 성공률**
- 두 지표에서 모두 베이스라인보다 큰 차이로 우수한 성능을 보임
- 베이스라인 vlm은 숫자로된 답변을 꺼리는 경향이 있음
- 아마도 학습 데이터의 분포 때문일 가능성
- spatialvlm은 카메라로부터 1~10m 거리의 중간 범위 장면에서 성능이 좋음
- 이는 사용된 monocular depth estimator가 정확한 깊이 추정을 제공하는 범위와 일치함
→ 데이터 생성 과정에서 사용한 비전 모델의 bias와 한계를 그대로 물려받았음을 의미함
- vlm 평가를 위한 2가지 메트릭 설계
- 4.2. 일반적인 VQA에 Spatial VQA 데이터의 효과
- 상당한 양의 spatial VQA 데이터를 함께 학습할 때 **다른 작업에서 VLM의 성능이 저하되는지**의 여부
PaLM 2-E와 우리 모델을 일반 vqa 벤치마크에서 비교함
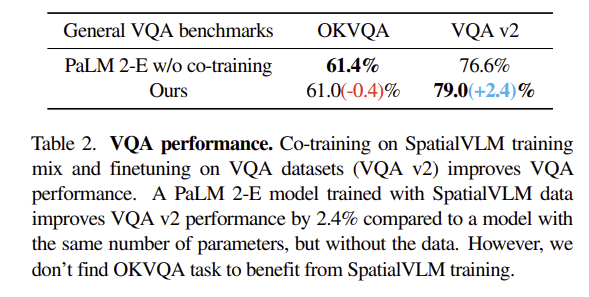
- 우리 모델이 PALM과 거의 유사한 성능
- 공간 추론 질문이 포함된 VQA v2에서는 오히려 더 좋은 성능
- vlm들이 공간 추론과 관련된 task 분포에서 전반적으로 underfit 상태임
- 그래서 공간 vqa 학습을 추가해도 일반 vqa 성능을 해치지 않으면서 오히려 도움이 될 수 있음을 의미함
4.3. 공간 추론에서 vision transformer의 역할
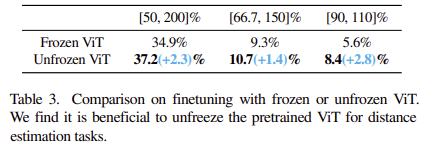
- contrastive objective로 학습된 frozen vit가 공간 추론을 수행하기에 충분한 정보를 담고 있는가
- 이를 분석하기 위해서 110k 학습 스텝에서 출발해서 vit를 freeze/unfreeze해서 각각 학습
- 두 모델을 각각 70k 스텝동안 학습하고, 각 모델의 답이 실제 값의 다양한 범위에 속하는 비율을 평가함
- 정답의 50~200% 거리 추정에서는 vit를 freeze한 것이 unfreeze와 거의 유사함
- 더 정밀한 거리 추정에서는 vit를 학습하는 것이 더 성능이 좋음
- 사전학습한 vit가 세밀한 공간 정보를 일부 손실하고 있다고 가정함
- 0.9~1.1배 범위에 들어가는 정확도에서 8.4%를 달성함
- 인간 annotation이 노이즈가 잇음에도 불구하고 의미있는 결과임 (사람은 노이즈가 있는 추정을 하는 경향이 있음)
- 다양한 도메인에서 vlm의 정량적 공간 추론 능력을 평가하는 것은 여전히 어려운 문제로 남아있음
- 4.4. 노이즈가 있는 정량적 공간 답변의 영향
- spatial vqa 데이터셋의 정량적 답변에 노이즈가 존재하기 때문에, 많은 양의 노이즈 데이터를 통해 vlm이 일반화 가능한 정량적 추정을 학습할 수 있는지를 봄
- depth camera로 측정된 거의 gt 수준의 깊이 정보를 제공하는 로봇 조작 데이터셋을 활용함
- 그 결과 생성된 정량적 답변은 더 정확해짐
이 데이터셋으로 vlm을 학습했더니 그 도메인에서 정밀한 거리 추정이 가능했음

정확한 데이터셋의 정량 답변에 가우시안 노이즈를 추가해서 다양한 수준의 노이즈 데이터셋을 생성

- 서로 다른 노이즈 수준으로 학습된 vlm은 유사한 공간 추론 정확도를 보임
학습 / 평가 데이터 모두에서 노이즈가 존재하기 때문이고, vlm이 노이즈 속에서도 공간 추론에 대한 일종의 상식을 학습하기 때문이라고 추정함

- 거리 추정을 통해 로봇 작업에 reward/cost를 줄 수 있음
- 다양한 그리퍼의 위치를 샘플링하고 그에 따른 cost 함수를 scatter plot으로 나타냄
- 모델이 강하게 정규화되어 있기 때문에 거리 추정이 평균값 쪽으로 치우치는 경향이 있음
- 4.5. Spatial reasoning이 가능하게 하는 새로운 응용
- dense reward annotator로서의 vlm
- vlm의 중요한 응용 분야 중 하나인 로보틱스
- 최근 연구들은 vlm과 llm이 로봇 작업에서 open-vocab 기반 범용 reward annotator 및 성공 판별기로 활용될 수 있고, 이로 인해 유용한 제어 정책을 학습할 수 잇음을 보여줌
- 하지만 vlm의 reward annotation 능력은 공간 인식 능력 부족으로 아직 제한됨
- spatialVLM은 정량적으로 거리나 크기를 예측할 수 있기 때문에 dense reward annotator로서 적합함
- 자연어로 작업을 정의하고, trajectory의 각 프레임에 대해 spatialvlm이 reward를 부여하도록 하는 실제 로봇 실험을 수행함
- cot 기반 공간 추론
- spatialvlm이 multi-step reasoning이 필요한 작업에 활용될 수 있는지 분석
- 대형 언어 모델인 gpt-4에 spatialVLM을 공간 추론 서브모듈로 결합하면 환경 내 3개의 객체가 이등변 삼각형을 이루는지 판단하는 등의 복잡한 공간 추론 작업을 수행할 수 있음
- dense reward annotator로서의 vlm
Conclusion
- 본 연구는 vlm에 공간 추론을 주입하는 문제를 다루며, 인터넷 규모의 실제 이미지 기반으로 3d 공간 추론 vqa 데이터를 자동 생성하는 프레임워크를 구축하는 방식으로 접근
- 대량의 노이즈 데이터로 학습하는 것과 vit를 unfreeze하는 것 등 다양한 학습 설계 요소를 분석함
- 학습한 직접적인 공간에 대한 질문은 제한된 템플릿 기반이지만, spatialVLM이 공간 추론에 필요한 더 복잡한 COT 문제로 확장될 수 있음을 보였음
- SpatialVLM은 로봇 작업에서도 유용하고, 3D 공간 인식을 갖춘 VLM이 로봇 작업의 reward annotator로 활용될 수 있음을 보임
- 더 정교한 기하학적 요소들에 대한 추가 연구는 spatial reasoning을 3d 기하 구조에 완전히 정착시키는데 도움이 될 수 있음
This post is licensed under CC BY 4.0 by the author.