GenRecon: Bridging Generative Priors for Multi-View 3D Scene Reconstruction
GenRecon: Bridging Generative Priors for Multi-View 3D Scene Reconstruction
- 2605 arxiv
- 뮌헨 공대와 화웨이 스위스
Related work
- reconstruction without learned priors
- colmap, mvs, nerf, monosdf, 3dgs 등
- 특징은 이미지에 실제로 보이는 정보만 사용한다는 것
- 장점: metric acc 좋고, hallucination 좋음
- 단점: 안 보이는 영역은 못 채움, sparse view에는 약함, occlusion에 약함
- reconstruction with learned priors
- vggt, dust3r, mast3r, depth anything 3
- 특징: 이미 학습된 geometry prior 사용 - feed forward로
- 장점: 관측 부족한 부분도 어느정도 복원
- 단점: 결국 regression이기 때문에, 진짜 안보이는 부분을 생성 못함
- 멀티뷰라서 gt가 많음 → gt를 최대한 맞추는데 학습이 집중됨
- generative prior 기반
- trellis, hunyuan3d 등
- 특징: 3d 생성 모델의 prior 사용
- latent distribution을 학습하는 것이 목표
- 기존 object level의 생성 모델을 scene level로 확장, multi view로 확장
Method
- overview
- 입력: sparse, unordered N개의 posed rgb 이미지들, 카메라 intrinsics와 extrinsics
- 출력: scene-level의 메쉬, pbr material
- 본 방법은 멀티뷰 recon과 강한 3d 생성 prior를 엮어서 사용 → 씬 복원을 씬을 커버하는 겹치는 씬 청크들을 생성하는 방법으로 치환함
- 3d prior로 Trellis.2를 사용 → 이건 object-level 3d prior이라서, 씬 청크 생성에 기반한 **멀티뷰 conditioning**을 도입함
전체 흐름
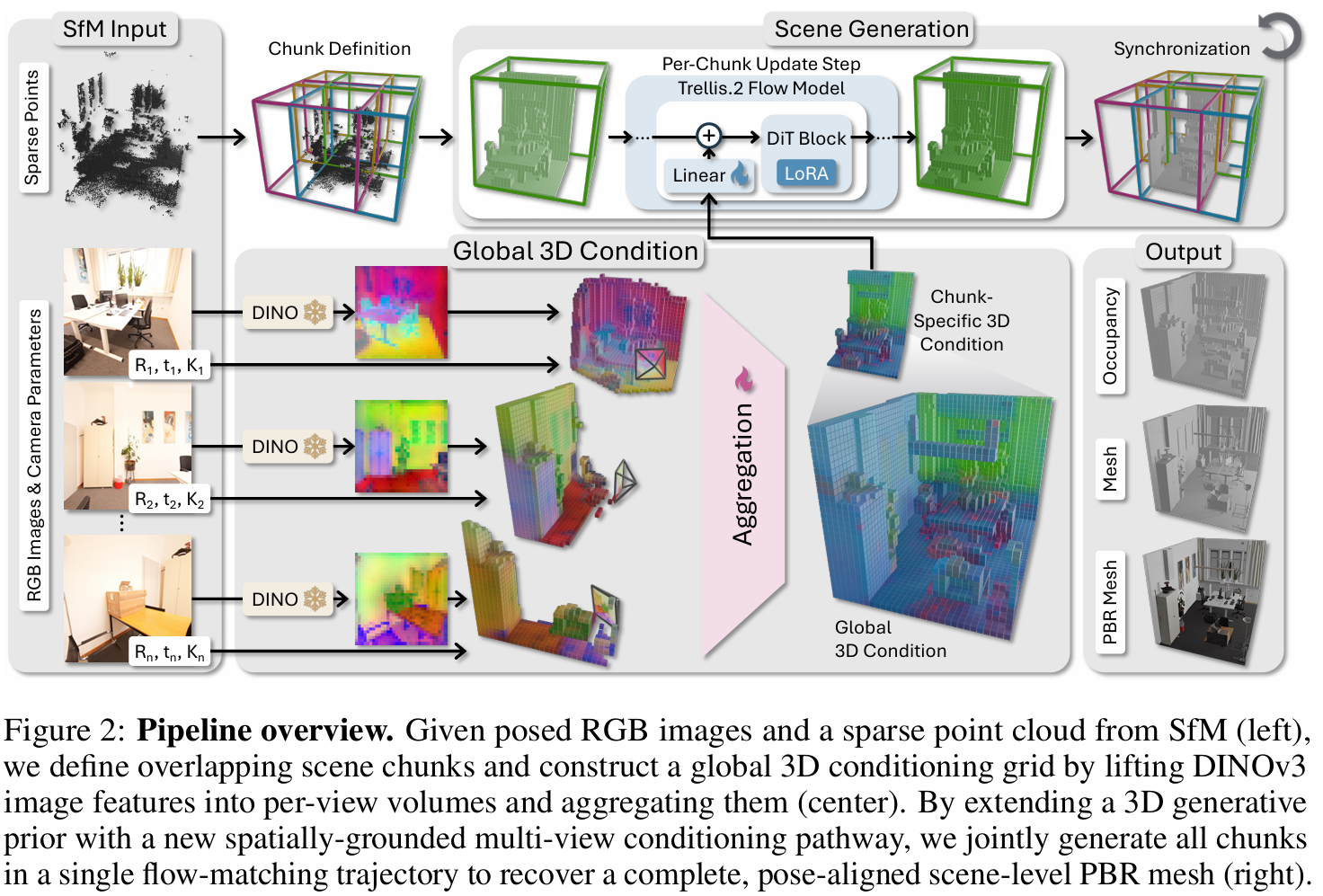
- 입력 이미지들에서 카메라 포즈와 sparse point cloud 얻기
- colmap
- 학습 시에는 posed rgb 이미지를 사용함 (camera intrinsics와 extrinsics 존재)
scene을 청크 단위로 분할
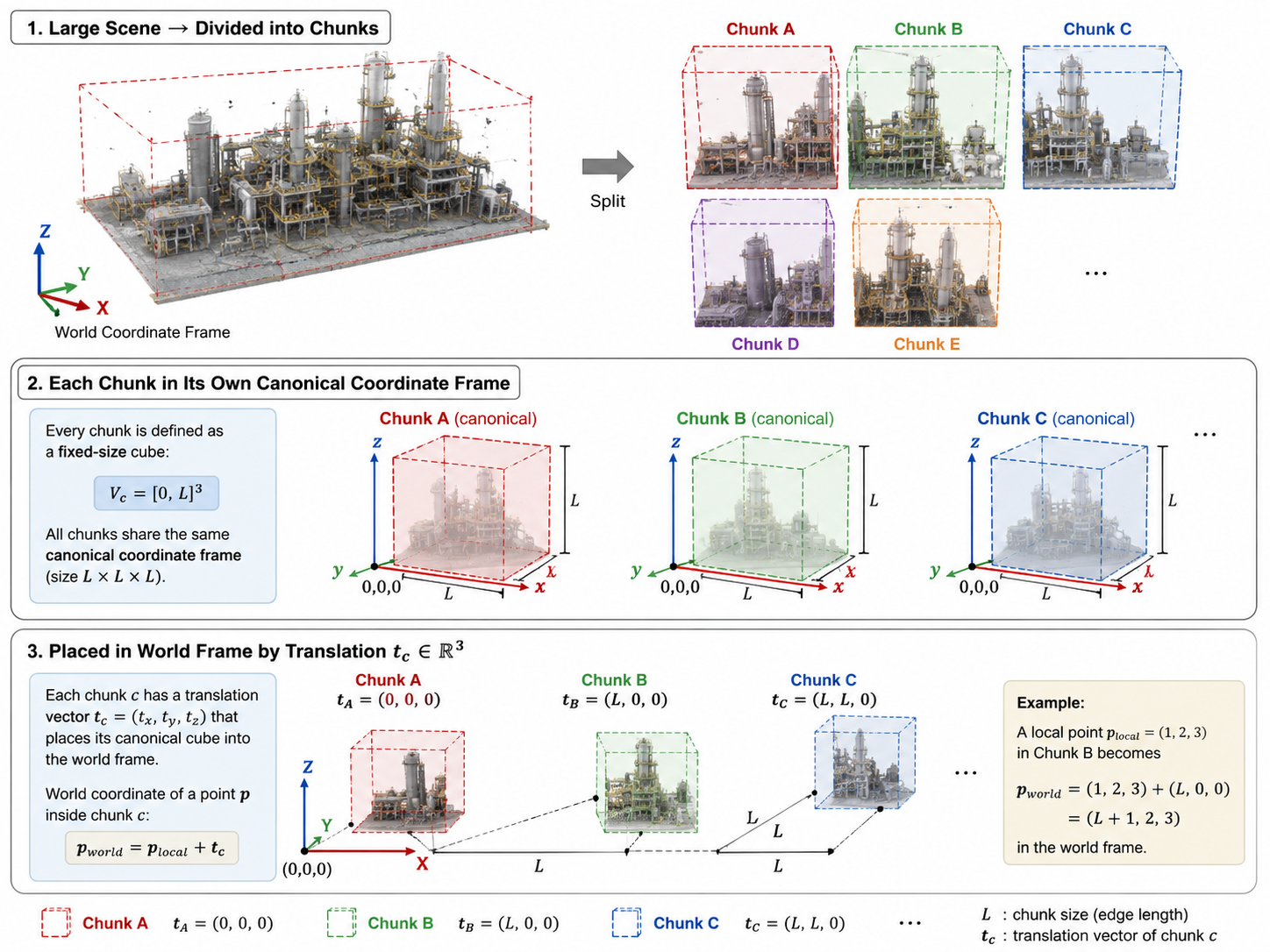
- 하나의 청크는 고정된 사이즈 ([0, L]^3)
- 이 청크는 해당 청크를 바라보는 입력 view의 집합과 연관됨 (해당 청크가 보이는 view)
- 청크끼리는 일부 겹침 → 경계를 자연스럽게 잇기 위함
- Scene ├── Chunk 1 │ ├── Voxel │ ├── Voxel │ └── … ├── Chunk 2 │ ├── Voxel │ └── … └── …
- 3d 생성 모델의 입력:
{(In, Kn, T⁻¹n Tc)}n∈VcIn: n번째 RGB 이미지Kn: 카메라 intrinsicTn: n번째 카메라 poseTc: chunk 위치 (world 좌표에서 어디 있는지)T⁻¹n Tc: chunk 위치를 현재 카메라 기준으로 변환해서 이 이미지에서 이 청크가 어디 보이는지를 알려줌- 어떤 카메라가 특정 청크를 보는지 결정 → 그 카메라들만 사용해서
T⁻¹n Tc결정- 어떤 카메라가 특정 청크를 보는가?
- chunk bbox 8개 corner → projection → 일부라도 image 내부인가?를 통해 확인함
- 어떤 카메라가 특정 청크를 보는가?
- DINO 피처 추출
- 입력 이미지(해당 청크가 보이는/앞에서 구한)의 DINO 피처를 추출
- 이 피처맵에서 해당 복셀이 보이는 영역에 해당하는 부분을 추출
- 각 복셀이 이미지 피처맵의 어디에 해당하는지 구함
- “이 voxel이 이미지 몇 번째 픽셀에 보이는가?”
1 2 3 4 5
Voxel A ↓ projection 피처맵의 (120,80) 위치 ↓ lookup DINO feature
- 2d feature가 3d 공간으로 올라가는 2d → 3d lifting
- 해당 청크가 보이는 멀티뷰를 사용하므로 멀티피처가 구해짐
- multi-view aggregation
- 여러 뷰의 피처를 하나로 합침
- IBRNet-style
- 먼저 멀티뷰 피처의 평균과 분산을 구함
- 각 멀티뷰 피처마다 mlp에 (멀티뷰 피처 i, 평균, 분산) 을 넣음 → _보정된 피처_를 얻음
- mlp는 보정된 피처를 얻는 mlp와 신뢰도를 얻는 mlp 2개로 이루어짐
- weight x 보정된 피처의 sum + 평균 피처로 최종 피처를 구함
- 최종 피처 = μ + Σ αi f’i
- residual connection 방식으로 처음에는 zero-초기화 → 평균부터 학습 시작
_**→ 품질이 좋은 뷰는 많이 반영하고, 품질이 안좋은 뷰는 적게 반영하도록**_
- trellis에 conditioning
- trellis.2 → sota 3d shape gen model
- coarse occupancy를 예측한 다음, shape과 pbr texture를 생성하는 방식
- 본 연구에서는 single unposed image를 입력으로 받는 trellis를 scene recon에 맞게 조정함 → **multi-view를 인식하고, multi-view가 하나의 일관된 set으로 들어가도록, 생성된 결과를 전체 좌표계 상에서 배치할 수 있도록**
- 기존 trellis는 image → cross attn → 3d generation
- 3d condition grid → dit block마다 residual injection → flow denoising
- 각 복셀별로 대응되는 피처를 넣음
- residual injection
- h (hidden vec) = h + condition
- trellis.2 → sota 3d shape gen model
- 학습
- lora 사용, 나머지 trellis weight는 frozen
- 합성 씬 데이터로 학습 - gt chunk latent랑 생성된 청크 사이의 차이 학습
- 입력 이미지들에서 카메라 포즈와 sparse point cloud 얻기
- 추론 과정
- 입력: 순서 없는 rgb 이미지의 집합
- 출력: scene-level pbr mesh
- scene calibration and chunking
- 이미지의 pose를 모르기 때문에 sfm (colmap)을 돌림 → camera intrinsic과 extrinsic, sparse point cloud를 얻음
- 이 sparse point cloud에 outlier 필터링을걸음
- scene의 공간적 범위 B를 추정함
- B를 가지고 장면을 청크로 분할함 - cube, 월드 좌표계로 돌아올 수 있는 translation matrix
- 이웃한 청크는 조금씩 겹치게 해서 생성할 때 연결성 유지 - 경계에서 geometry가 끊어지지 않도록
- global 3d conditioning
- 매번 피처 lifting을 해서 복셀의 피처를 구하지 않음
- 멀티뷰 이미지들을 dino 피처를 먼저 구하고, 3d lifting을 통해 voxel에 매핑하고, 각 voxel은 멀티뷰 피처를 aggregation한 global conditioning grid G를 구축함
- occupancy 생성 시에는 낮은 해상도를 가지고 dense함 → 0 or 1
- shape, texture 생성 시에는 더 높은 해상도를 가지고 sparse함 - 유효 복셀만 보기 때문, 디테일을 포착하기 위해서 높은 해상도 사용
joint chunk generation
현재 step의 Global latent zt 유지
각 chunk 영역을 crop (z(A), z(B), z(C), …)
각 chunk에 대해 TRELLIS denoiser 수행 (z(A) → ẑ(A), z(B) → ẑ(B), z(C) → ẑ(C))
다시 Global latent로 merge
- overlap 영역: 여러 chunk 예측의 평균
- boundary voxel: 평균 계산에는 참여 X, 평균 결과로 업데이트는 O
새로운 Global latent zt-1 생성
다음 denoising step 반복
This post is licensed under CC BY 4.0 by the author.