SAM 3D: 3Dfy Anything in Images
SAM 3D: 3Dfy Anything in Images
- cvpr 2026
- meta sam3d 팀
배경
- 기존 3d 생성 모델은 objaverse와 같이 고립된 single object 데이터로 학습되어 실제 사진 속 객체를 복원하는데 한계가 있었음
- 특히 실제 환경에서 일어나는 가림, 복잡한 배경, 원거리 객체 등에 대한 대규모 학습 데이터 부족
- 본 연구는 자연 이미지 속 객체의 형상, 텍스처, 레이아웃까지 복원할 수 있는 범용 3d 파운데이션 모델인 sam 3d를 제안함
방법론
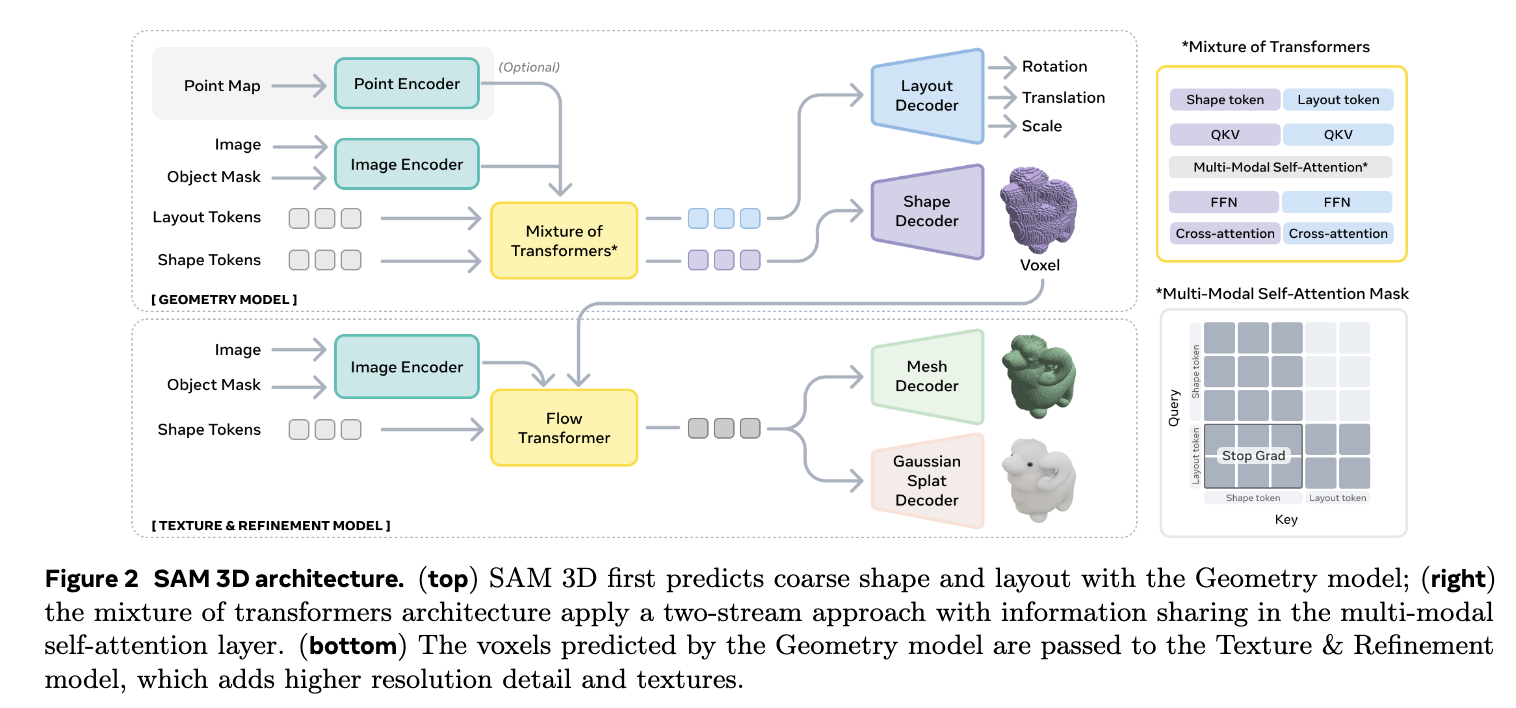
- 입력: 단일 이미지, 객체 마스크 (원하는 위치 지정)
- 객체의 형상, 텍스처, 위치, 자세를 복원하는 2단계 구조를 설계함
- geometry model이 객체의 rough한 형상과 3d 배치 정보를 예측
- 이후에 texture-refinement 모델이 세부 형상과 텍스처를 생성함
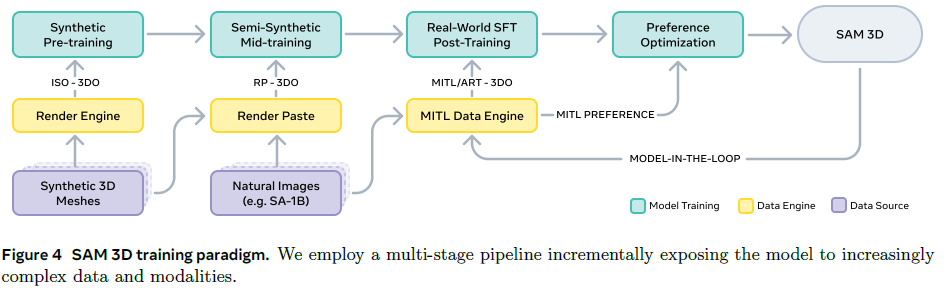
- 학습
- stage 1: objaverse 기반 270만개 에셋으로 synthetic 사전학습
- stage 1.5: 실제 이미지 위에 3d 객체를 합성한 semi-synthetic 데이터로 mid-training 수행
- stage 2: model in the loop 엔진을 활용해 실제 이미지에 대한 3d 주석을 수집하고 sft/dpo 수행
- 모델이 생성한 3d 후보 중에서 사람이 가장 적절한 결과를 선택하고 정렬하는 방식
- 약 100만장의 이미지와 314만개의 주석 데이터를 확보함
- 모델 구조는 trellis에서 따온듯
기여점
- 자연 이미지 속 객체의 형상, 텍스처, 위치를 동시에 복원할 수 잇는 sam 3d
This post is licensed under CC BY 4.0 by the author.