Why We Feel: Breaking Boundaries in Emotional Reasoning with Multimodal Large Language Models
Why We Feel: Breaking Boundaries in Emotional Reasoning with Multimodal Large Language Models
CVPR 2025 Workshop
Emotion interpretation이라는 task를 새로 제시, 벤치마크 데이터셋 (+평가 기준) 제시
”한 인물의” 감정에 집중함 - 전체 장면에 대한 감정은 아님
학습 x 평가만 o (평가에 대한 데이터셋 + 지표 제시한 것이 novelty)
Abstract
- 기존 감정 분석은 “어떤 감정이 발생하는가?” —> “왜 발생하는가?”
- Emotion interpretation이라는 새로운 task 제시 - 감정 반응을 유발하는 원인을 중점적으로 다룸 (명시적 요인 / 암묵적 요인)
- 감정을 촉발하는 요인에 대한 추론
- EIBench라는 대규모 벤치마크 제시함 - 기본 EI 샘플 1,615개, 다면적 감정을 포함하는 복합 EI 샘플 50개
- 단순한 분류가 아니라 이유 기반 설명을 필요로 함
- Coarse-to-Fine Self-Ask annotation 파이프라인을 제공함
- VLM이 반복적인 QA를 통해 대규모로 고품질 라벨을 생성할 수 있도록 함
- 4가지 광범위한 평가 - EI가 공감적이고 맥락을 이해하는 AI 응용을 풍부하게 만들 수 있는 잠재력을 보여줌
→ 왜 그런 감정이 생겼는지에 대한 원인을 분석하자!!
Introduction
- 최근 감정 인식 - 사용자가 행복한지 슬픈지 예측, 왜 그런 감정이 생겼는지에 대한 근본적인 질문은 간과되고 있음
- 감정은 미묘하고 주관적이라서, 단순히 감정을 라벨링하는 것만으로는 그 감정을 유발한 진짜 요인을 충분히 설명할 수 없음
- EI의 필요성
- 어떤 사용자의 감정을 단순히 파악하는 것을 넘어서, 왜 그런 감정이 유발되었는지에 따라서 대응방식이 달라짐
- 요인
- 명시적 요인: 관찰 가능한 객체, 사람 간의 상호작용 등
- 암묵적 요인: 문화적 배경, 화면 밖의 맥락, 숨겨진 이야기 등
- VLM은 시각적 단서와 세계 지식을 통합해서 설명적인 텍스트를 생성할 수 있는 가능성을 지님
- 기존 감정 데이터셋의 한계
- 주로 “분류”용, 감정 유발 요인을 포함하지 않음
- 이에 대응해서, EIBench 데이터셋을 제공함
- 기본 1615개 샘플, complex 50개 샘플
- main contribution 요약
- task 정의: EI - 단순 감정 라벨링을 넘어서 개인의 emotion state의 요인을 파악함, 공감력이 있고 맥락을 아는 ai로 갈 수 있게 함
- benchmark dataset: EIBench - 기본 샘플은 4가지 category (화남, 슬픔, 기쁨, 흥분), complex 샘플은 다중 감정이 얽힌 복잡한 시나리오, 감정 해석의 다양한 측면을 평가할 수 있게 해줌
- annotation pipeline: Coarse-to-Fine Self-ask
- CoT 추론을 기반으로 한 다단계 질의응답 기반 주석. 고성능 vlm을 활용해서 명시적/암묵적 원인을 포착하는 고품질 라벨을 반자동으로 생성함
- 포괄적 평가: 공개 및 사내 LLM을 대상으로 다양한 입력 조건에서 실험 - 단순 EI에서는 일부 모델이 우수했으나, 복잡한 다중 시나리오에서는 성능이 저하됨. → 보다 정교한 해석 필요성 강조
Related work
- context-aware emotion recognition - facial expression recognition, context-aware emotion recognition (이것도 마찬가지로 표정 인식, FER보다 더 넓은 정보를 활용해서 감정 추정 정확도를 높인 확장형 task)
- Emotion Recognition with LLMs
- 설명 가능한 emotion recognition
- chain-of-thought prompting 사용, retrieval-augmented pipelines 사용, VLM이 이미지 기반 추론 가능
- Humor Study
- 감정적 현상 중에서 특별한 분야, 많은 주목을 받아옴
- 웃음을 유발하는 요인 분석
- EI는 더 포괄적인 개념
- Emotion Cause Extraction
- 주어진 감정에 대해서, 그것을 설명하는 text나 멀티모달 단서를 찾는 작업 - 생성은 아님!
- 이 task는 주로 주어진 입력 내부에서 원인을 찾는 반면에, EI는 암시적/화면 밖의 맥락까지 포함하고 생성적인 감정 유발 요인을 스스로 구성, 더 깊은 설명 생성함
- Chain-of-Thought Prompting
- CoT: llm이 중간 추론 과정을 단계적으로 말하게 함으로써 문제 해결 능력을 향상시키는 방법
- CFSA: LLM의 내적 추론 구조화를 따르되, 감정 해석에 특화됨
- 일반적인 질문에서 시작해서, 상황 특화된 감정 유발 요인 분석으로 fine-grained됨
- 감정의 명시적 → 암묵적 요인까지 파악 가능 - 더 깊은 감정적 추론 가능케 함

Problem Definition
Proposed task
- 이미지 x: 얼굴 정보 x_face, 넓은 맥락 정보 x_context
- 감정을 유발한 트리거 집합 T를 생성하는 것을 목표로 함
- 입력: (이미지, 감정)
- 출력: 감정을 유발한 요인들의 집합 T

생성함수 G가 (이미지, 감정)을 입력으로 받아서 가능한 트리거들을 모아 T라는 트리거 집합을 예측함
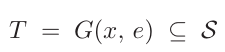
- 이 T 내의 trigger_i는 다음 두 종류 모두 가능함
- 자유 형식의 문장 기반 설명
- 간결한 태그
- S는 모든 가능한 전체 트리거 집합
- 이 T 내의 trigger_i는 다음 두 종류 모두 가능함
Emotional Triggers
- 감정 트리거를 개인의 감정 반응을 “유발하거나 변화시키는 자극”으로 정의함
- 트리거 종류
- τ_env : 환경적 요소, 분위기
- τ_social: 사회적 상호작용 - 관계, 대화
- τ_phys: 신체적 단서 - 표정, 자세, 몸짓
- τ_obj: 의미있는 객체
- 명시적/암묵적 트리거
- τ_explicit, τ_implicit
- EI는 숨겨진 암묵적 트리거까지 고려함으로써 더 풍부하고 정교한 감정 해석이 가능함!
Emotion Interpretation Benchmark

- EIBench - CAER-S, EmoSet을 기반으로 구축
- 특정 감정이 “왜” 발생했는지를 설명하기 위해 설계된 최초의 데이터셋임
- 기본 EI: 1615개
- 복합 EI: 50개
VLLM-Assisted Dataset Construction
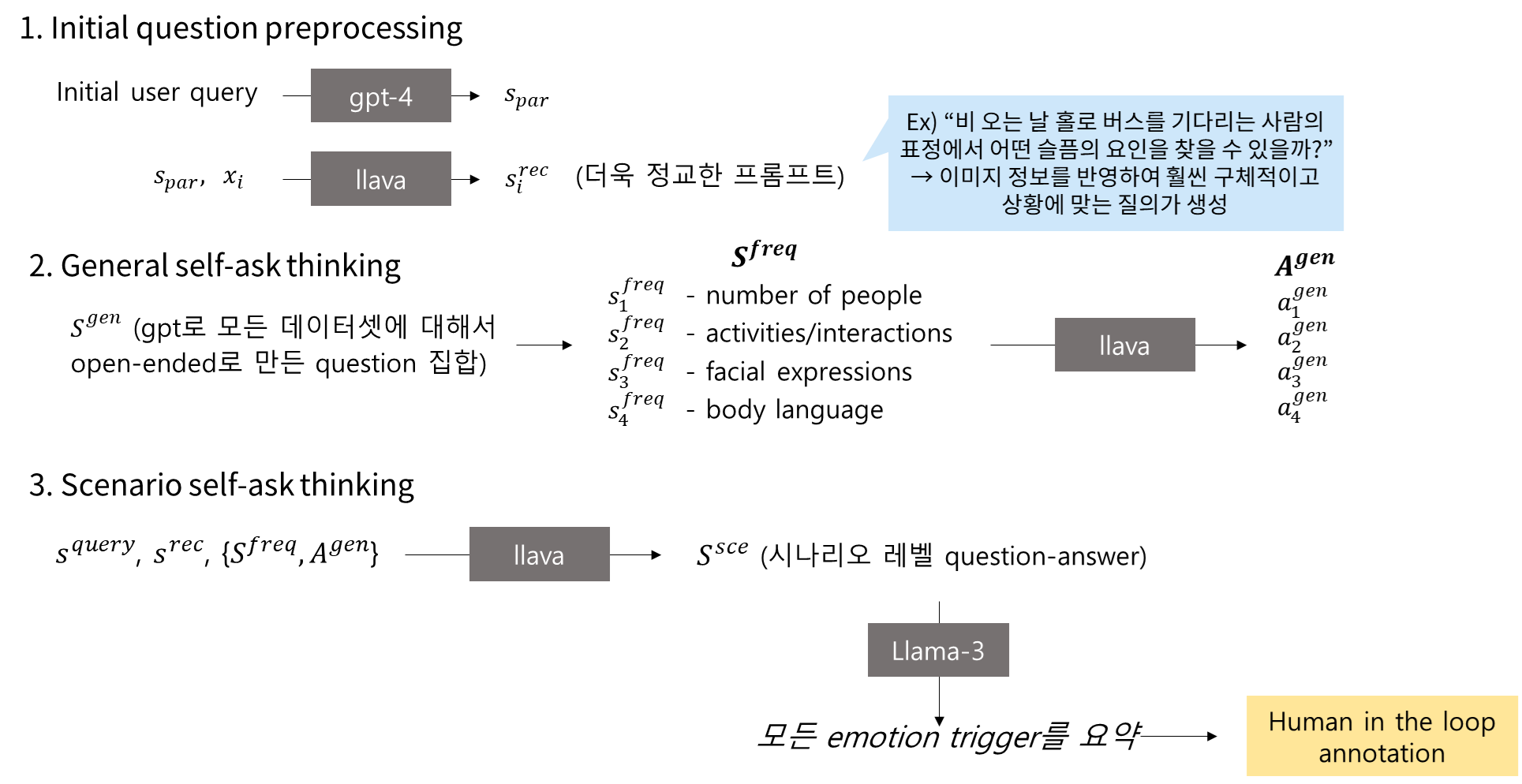
- Coarse-to-Fine annotation
- implicit query를 여러 단계의 간단한 VQA task로 분해함
- Initial question preprocessing
- General self-ask thinking
- Scenario self-ask thinking
- Emotion summarization
- 자동화 단계 이후에 4명이 철저하게 검수함
- implicit query를 여러 단계의 간단한 VQA task로 분해함
- Initial question preprocessing
- gpt-4가 사용자의 초기 query를 풍부하게 만듦
- s^par = φ(s_init)
- 이미지 x_i가 있을때 llava를 사용해서 더욱 정교한 프롬프트를 만듦
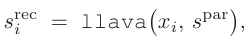
- vlm이 많은 시각적 디테일을 보긴 하지만, 미묘한 감정 단서들을 간과함 → self-ask 단계
- gpt-4가 사용자의 초기 query를 풍부하게 만듦
- General self-asking
- gpt-4를 이용해서 전체 데이터셋에 대해 open-ended question을 생성하도록 함 → S^gen
- 이 중에서 자주 등장하는 4가지 질문을 뽑음
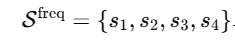
- 주제 - 등장 인물수, 활동이나 상호작용, 얼굴 표정, 몸짓/자세
- 위 질문에 대해 llava가 이미지 기반 답변을 만듬 → A^gen
- Scenario Self-Asking
- user 쿼리, reconstruct된 s_rec, 앞단계에서 구축한 {S_freq, A_gen}을 llava에 입력함 →
- S_sce: 시나리오 수준의 정교한 질문
- 고도화된 LLM이 지금까지 수집한 모든 응답을 통합해서 “감정 유발 요인”을 요약함
- 입력
사용자 질의 s_query
정제된 프롬프트 s_rec (초기 질문 보강)
General Self-Asking 결과:
- 자주 쓰이는 일반 질문 S^freq
- 그 질문들에 대한 LLaVA의 답변 A^gen
Scenario Self-Asking 결과:
- 시나리오 기반 질문 S^sce (LLaVA 생성)
- 그 질문들에 대한 LLaVA의 응답 (implicit, 논문에 a_sce_i 같은 기호는 없지만 암묵적으로 존재)
- 상황에 맞는 감정 유발 요인을 정밀하게 추론하는 단계
- user 쿼리, reconstruct된 s_rec, 앞단계에서 구축한 {S_freq, A_gen}을 llava에 입력함 →
- Human In-the-Loop Annotation
- 전 단계에서 얻은 자동 감정 해석결과는 기본 자동 라벨로 사용됨
- 4명의 인간 annotator가 3단계를 통해 라벨을 정제함
- 환각 제거
- commensense knowledge 추가 - 모델이 놓친 사회/문화적 맥락
- 관련 없는 트리거 제거 - 감정과 무관한 설명 제거
- 라벨 품질 검증을 위해, 감정 카테고리 별로 랜덤하게 50개 이미지를 추출해서 3명의 검토자가 트리거의 품질에 대해서 0~5점 척도로 평가함
- 3점 미만은 트리거가 부정확하거나 불완전한 경우
- → 최종 평가 점수는 모두 4점 이상 기록함 -< EIBench의 주석 품질이 신뢰할 수 잇다는 것을 뜻함
Dataset Overview & Evaluation
- Data Sources
- CAER-S: 7가지 감정 카테고리
- EmoSet: 8가지 감정 카테고리
- 이 중 4개만 사용: angry, sad, excited, happy
- Data Composition & Trigger Distribution
- 4개의 감정 카테고리가 fine-grained하게 나눠짐
- 트리거는 10개의 큰 카테고리로 나눠짐 ex. atmosphere, social interactions, body movements …
- Comparison with Existing Datasets
- explainable: dataset이 explanatory or causal annotation을 포함하는지
- has complex label: multi-layer or 더 nuanced한 labeling이 있는지
- Evaluation metrics
- emotional trigger recall : 예측된 트리거가 정답으로 주어진 트리거와 겹치는지 확인.
- longterm coherence: 모델이 긴 출력에서 주제적, 감정적, 일관성을 유지하는지 확인.
- BERT 기반 방법으로 sentence-to-sentence 유사도를 평가함
Experiments
Experimental Setup
- 어떻게 LLM이 EI를 조사했는지에 대한 4가지 모드를 도입함
- User Qustion: zero-shot 시나리오, 사용자의 질문을 있는 그대로 제공함.
- 자연스럽고 모호한 question에 대해서 모델이 대응하는 능력을 점검함
- User Question + Caption: 사용자 질문에 캡션을 추가함 - 문맥을 정확히 함
- User Qustion + CoT: let’s think step by step 추가함.
- CFSA: 본 연구에서 제시하는 방식
- User Qustion: zero-shot 시나리오, 사용자의 질문을 있는 그대로 제공함.
Basic EI results
- llava family, minigpt-v2가 잘 동작함, qwen-vl-chat은 lagging함
- video-llava랑 otter가 미드 티어였음
- claude랑 chatgpt (closed) user-question setting에서 잘 동작하였음
- qwen-vl-plus는 잘 못함
Complex EI results
- 탑 오픈 소스 모델 (llava-1.5)가 chatgpt의 성능에근접해짐
- claude-3가 basic에서는 엄청 잘했는데, complex에서는 탑은 아님 → 다면적인 감정 문맥을 파악하는 것을 어려워함
Long-term coherence
- bert-based similarity로 측정함
- 대부분 80~86% - 긴 출력에서도 감정적 일관성을 유지함
- 점수는 전반적으로 높지만, 감정을 정확히 이해하고 해석하는 능력이 뛰어나다는 걸 의미하는건 아님
Ablation on Persona Prompts
- 다른 persona가 EI performance에 영향을 주는지 테스트해봄
- 세팅
- no persona
- AI Asisstant persona
- architecture expert
- Emotion expert
- “Emotion expert”일때 일관되게 높은 점수를 보임 → domain specific한 persona가 emotion trigger에 대한 cot를 도움
- “architecture”는 성능 저하시킴
⇒ well-chosen persona + target domain은 LLM을 더 정확하게 context-driven EI 해석을 하도록 이끔
Analysis of evaluation modes
- user question < user quetion + “caption”
- user qustion < user quustion + “CoT”
- CFSA가 가장 높은 성능 - 68% / 사람 annotation 수준은 아님
Key observations and limitations
- 인간 수준 annotation과의 격차 → 보다 정교한 instruction tuning과 복잡한 문맥을 더 잘 이해하는 모델링 기법의 필요성을 강조함
- 더 어려워하는 감정이 있음, complex 혼합 감정은 어려움
- 오픈 소스 모델보다 closed가 더 좋은 성능을 보임
Conclusion
- 본 연구는 어떤 감정이 있는가 → “왜 그 감정이 발생했는가?”
- EI를 위한 EIBench를 소개 - 명시적 단서와 암묵적 단서를 통해 정서 상태의 “원인”을 파악함
- CFSA 파이프라인 도입, 오픈 소스 및 closed 모델 평가 → EI가 AI의 공감 능력와 문맥 인식 능력을 향상시킬 수 있는 가능성을 보여줌
- 한계
- 겹치는 감정, 미묘한 단서에 대한 어려움
- 데이터셋이 모든 시나리오를 포괄하지 못함
- 평가 지표들도 정교함이 부족
- future work
- audio, text 대화와의 통합
- 미묘한 감정의 중첩을 처리할 수 있는 인과 모델링 확장
- 사용자 맞춤형, 동적인 상황에 대응할 수 있는 평가 프로토콜 개발
Github repository
https://github.com/Lum1104/EIBench
- EIBench/EI_Basic/basic_ground_truth.json: basic 샘플 정답
- EIBench/EI_Basic/user.jsonl: basic 샘플 query
- EIBench/EI_Complex/ec_complex.jsonl: complex 샘플 query/정답
This post is licensed under CC BY 4.0 by the author.