LLaVA: Large Language and Vision Assistant
LLaVA: Large Language and Vision Assistant
Visual Instruction Tuning
NIPS 2023
→ LLM에 이미지 인식 능력을 더해준 것이 특징
–참고–// LLaVA
Abstract
- machine-generated instruction-following 데이터로 LLM을 instruction tuning하는 것은 새로운 task의 zero-shot 성능을 향상시킴을 보여줌 / multimodal 분야에는 적용되지 않았음
- language-only GPT-4가 멀티모달 language-image instruction following 데이터를 생성하게 함
- 이 생성된 데이터로 instruction tuning을 한 모델인 LLaVA를 제시함 - LLaVA는 end-to-end로 훈련된 mllm이며, 일반적인 visual and language 이해를 위해 vision encoder와 LLM을 연결한 모델임
- 2개의 평가 벤치마크 제시
- instruction tuning 데이터, 모델, 코드 공개함
Introduction
- 인간은 vision과 language 등 여러 채널을 통해 세상과 소통하며, 각 채널은 특정한 개념을 전달하기 위한 각각의 이점이 있음(ex. 언어가 유리한 경우, 이미지가 유리한 경우…)
- 실세계의 task를 수행할 수 있는, multi-modal vision-and-language instruction을 따르는 일반적인 목적의 assistant를 개발하는 것이 중요함
- 연구자들은 실세계의 비주얼 이해 능력이 있으며 language-augmented된 foundation vision 모델을 만드는 데 집중함
- 기존 연구들은 하나의 큰 비전 모델에 의해 각 task가 독립적으로 수행됨 + language는 이미지 내용을 설명하는데에만 사용됨 → 모델이 고정된 인터페이스를 가지며, 사용자의 instruction에 대해서 상호작용능력과 적응력이 낮음
- 하지만 LLM은 보편적인 인터페이스를 가지는 general-purpose assistant가 될 수 있음을 보여줌
- 명시적인 자연어 형태의 여러 task instruction을 모델이 이해할 수 있음
- end-to-end로 훈련되어 풀고자 하는 task를 바꿀 수 있음
- ex. ChatGPT, GPT4
- LLaMA는 GPT-3의 성능과 비슷하며 오픈소스로 공개됨
- Alpaca, vicuna, gpt-4-llm 등은 machine-generated 고퀄리티 instruction-following 샘플들을 사용해서 LLM의 alignment 능력을 개선시킨 모델들임 → 이 연구들은 모두 text-only 형태임
- 본 연구는 instruction tuning을 language-image 멀티모달 공간에 적용하는 첫번째 연구인 visual instruction tuning을 제시함 → 일반적인 목적의 visual assistant를 만드는 것이 목적
- Contribution
- Multimodal instruction-following data: key challenge는 vision-language instruction following 데이터가 부족하다는것임. 본 연구에서는 image-text pair를 적절하게 instruction following 포맷으로 바꿀 수 있는 데이터 변형 관점/파이프라인을 제시함(Chatgpt/GPT-4 사용).
- LLM: open-set visual encoder인 CLIP과 language decoder Vicuna를 연결한 LLM을 구축함. 본 연구가 만든 멀티모달 instruction data로 fine-tuning
- Multimodal instruction-following benchmark: 2개의 어려운 benchmark인 LLaVA-Bench를 제시함, 다양한 paired image, instruction, annotation
- 오픈소스: 데이터, 코드, 모델, 데모
Related Work
- Multimodal Instruction-following agents
- Instruction tuning
- visual instruction tuning: 모델의 instruction-following 능력을 개선하는 것이 목적
- visual prompt tuning: 모델 adaptation에서 parameter-efficiency를 개선하는 것이 목적
GPT-assisted Visual Instruction Data Generation
- multimodal 데이터 (image-text pair)는 많아도, multimodal instruction-following 데이터는 별로 없음 - 데이터 구축하는데 시간이 많이 들고 사람한테 맡길 때 명확하게 정의되기 어렵기 때문
- text annotation task에 있어 gpt 모델의 성공 ⇒ 본 연구도 ChatGPT/GPT-4를 multimodal instruction-following 데이터 수집에 사용함, 기존 image-text pair에 대해서 돌림
- 방법 1
이미지 x_v, 캡션 x_c가 있을 때, GPT-4가 이미지 내용을 묘사하도록 지시하는 질문 세트 x_q를 만들도록 함

지시문과 답변 모두에 있어서 다양성과 심층 추론이 부족함
- 이 문제를 완화하기 위해서, 방법 2
- language-only인 GPT-4와 ChatGPT를 strong teacher로 사용함
- gpt에 visual features를 인코딩해서 입력할 때 두가지 symbolic representation을 사용함 → 이미지를 LLM이 인식할 수 있는 sequence로 인코딩함
- captions: 여러 관점에서 장면을 묘사함
bounding boxes : 장면 내의 객체들을 표시 - 하나의 box는 객체 개념과 위치를 인코딩함

- COCO 이미지 - 3가지 타입의 instruction following data (위 사진에 3가지 타입 있음)
- conversation: 어시스턴트가 이미지를 실제로 보고 질문에 답하는 것처럼 작성됨
- 이미지 내용, 객체 타입, 객체 수, 객체의 행동, 위치, 객체들 간의 상대적인 거리 등
- 명확한 답변이 존재하는 것에 대한 질문만 있음
- detailed description: 이미지에 대해 풍부하고 포괄적인 묘사
- GPT-4에 질문 목록을 생성하도록 요청한 뒤 그 중에서 하나를 랜덤으로 뽑음
- 그 질문에 대한 자세한 묘사(답변)를 GPT가 작성하도록 함
- complex reasoning: 이미지 내용 자체에 대한 위의 두 타입과 달리, 심층적인 추론과 관련된 문제
- 일반적으로 엄격한 논리를 따라 단계별로 추론 과정을 거쳐 답변을 만듦
- conversation: 어시스턴트가 이미지를 실제로 보고 질문에 답하는 것처럼 작성됨
- 사람 annotator가 몇가지 예제를 만들고, 이후에는 GPT가 in-context learning을 통해 예제를 기반으로 QA 데이터를 만듦
- 데이터 수: 158k(15만 8천개) instruction-following samples, 58k conversations, 23k detailed description, 77k complex reasoning
- ablation study로 ChatGPT와 GPT-4도 비교 - GPT4가 일관성 있게 더 고품질의 데이터를 생성함
Visual Instruction Tuning
- Architecture
목적: 사전학습된 LLM과 visual 모델의 능력을 모두 효과적으로 끌어내는 것
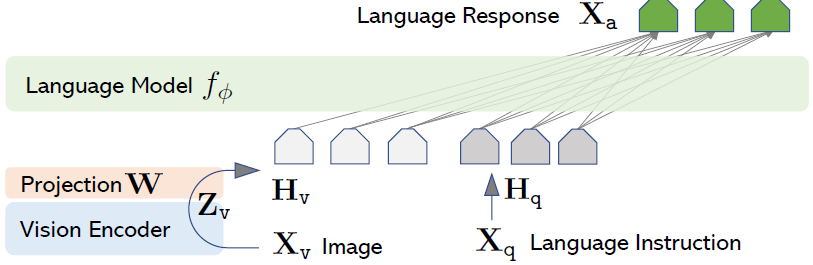
- LLM으로 Vicuna 사용 - 공개된 모델 중에 language task에서 instruction following 능력이 제일 높음
- visual encoder로는 CLIP visual encoder ViT-L/14 사용 - 마지막 transformer layer 전/후 grid feature를 사용함
- visual feature z_v는 linear layer를 통해 word embedding space로 project됨 → H_v (visual token의 sequence)
- linear layer라는 가벼운 방법을 사용함 / 더 복잡한 방법들 (cross-attention, Q—former 등)은 future work로 남겨둠
- Training
- 하나의 이미지 x_v에 대해서, multi-turn conversation data를 생성함, T개의 turn에 대하여
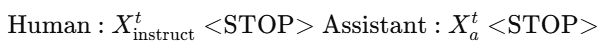
- [t = 1] x_instruct = (x_q1, x_v) or (x_v, x_q1)
- [t > 1] x_instruct = x_qt
- 입력 sequence 형태 - 모델은 초록색 글씨 부분을 예측해야함 (assistant answer, 어디서 stop하는지)

- instruction tuning - 기존 LLM의 auto-regressive한 training objective를 사용함
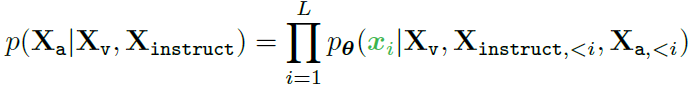
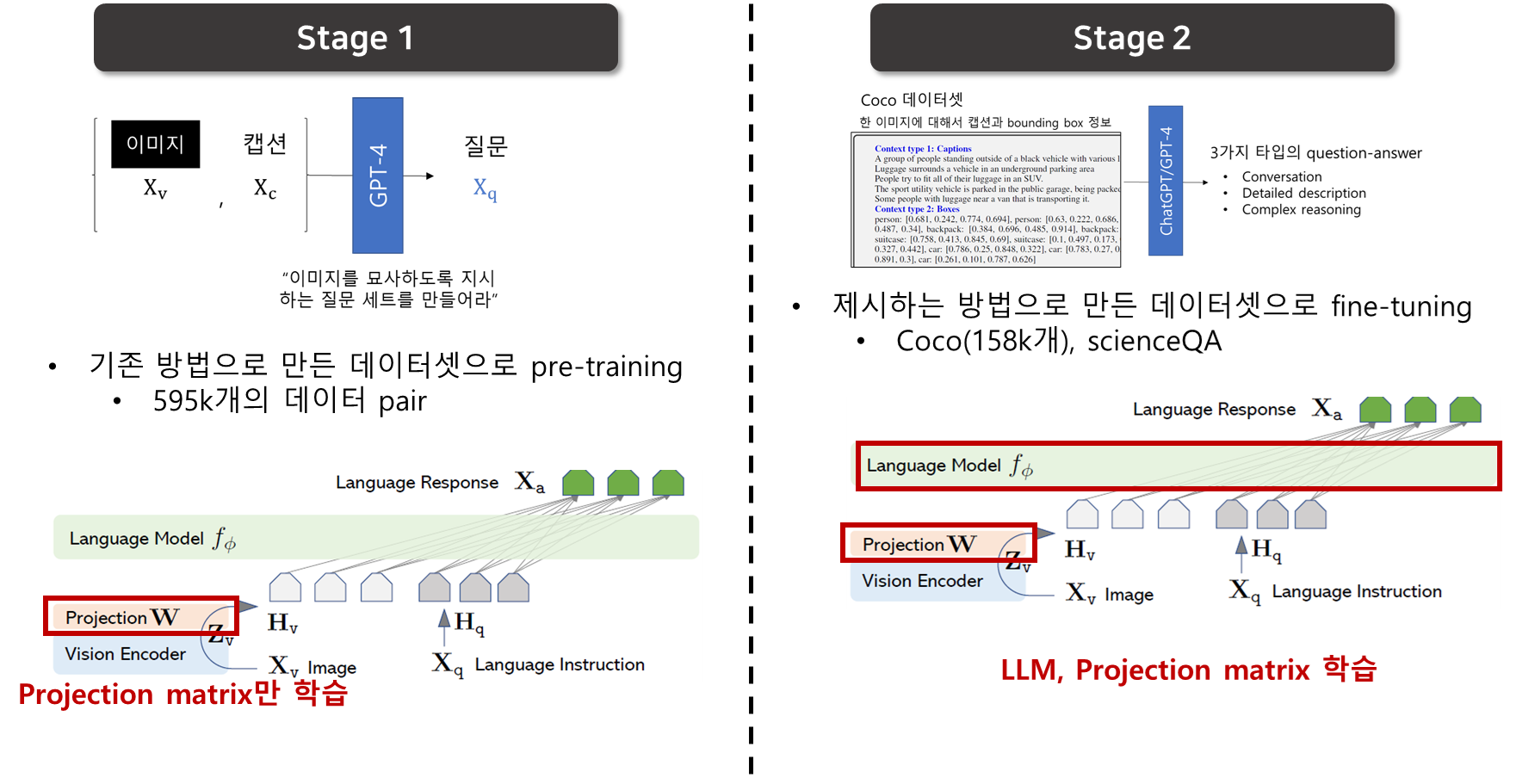
Stage 1: Pre-training for Feature Alignment
- concept coverage와 학습 효율성 사이의 balance를 맞추기 위해서, CC3M을 595K개의 image-text pair로 필터링함 → 앞 데이터 섹션의 데이터 형식으로 바꿈(instruction 생성)
- 하나의 QA 샘플은 single-turn conversation으로 간주함
- 방법 1을 사용해서 데이터셋 구축 : x_v 이미지 1개에 대해서, 이미지를 묘사하는 x_q 질문이 랜덤하게 샘플링이 되고 이 질문이 instruction이 됨, ground-truth 정답은 오리지널 캡션임
- LLM과 visual encoder는 frozen하고, align역할의 linear layer만 학습이 됨
- 이 stage는 frozen LLM에 align할 수 있도록 visual tokenizer를 학습시키는 과정
Stage 2: Fine-tuning End-to-End
- linear layer와 LLM을 fine-tuning함, visual encoder는 frozen 상태
- multimodal chatbot : 158k language-image instruction data (앞서 구축한 데이터셋)으로 fine-tuning함. 데이터의 3가지 타입 중에 conversation은 multi-turn이고, 나머지는 single-turn임. 이 데이터들은 학습에서 uniform하게 샘플링됨
- Science QA : 대용량 multimodal 과학 문제 데이터셋인 ScienceQA 벤치마크에 대해서 연구함. 질문 하나는 자연어 형태로 context(자연어 or 이미지) 와 함께 제공됨.
- 모델은 추론 과정과 정답을 동시에 예측, 여러 선택 중에 정답을 선택함
- single-turn conversation
- X_instruct: question & context, X_a: reasoning & answer
Experiments
5.1. Multimodal Chatbot
- 정성적인 평가
- 예시 입력 이미지와 instruction을 줌
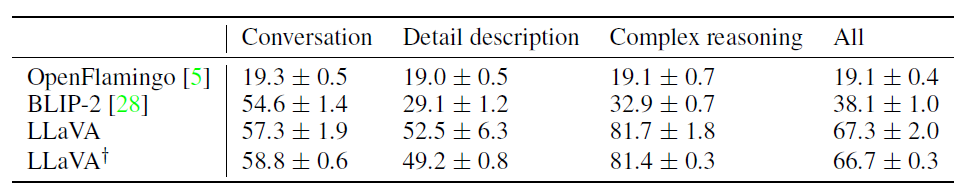
- 베이스라인 모델인 GPT-4보다 더 포괄적인 답을 함, BLIP-2, OpenFlamingo보다 더 instruction을 잘 따름
Quantitative Evaluation
- gpt-4가 생성된 응답을 평가하도록 함
- 입력 데이터 : (이미지, GT 텍스트묘사, 질문)
- 모델이 질문과 이미지를 기반으로 답을 예측함
- 비교군으로 GPT4가 만든 참조 예측을 사용함 - 참조 예측은 (질문, GT 텍스트 묘사)를 주었을 때 gpt가 생성한 답변으로 최상의 답변이라고 가정함 → “이론적 상한선”
- 평가는 GPT-4에게 (질문, 텍스트 형식의 비주얼정보, 두 모델이 만들어낸 응답)을 입력함
- helpfulness, relevance, accuracy, and level of detail of the responses를 평가 후 1~10점 사이의 점수를 매김(높을 수록 좋은 것)
- 평가에 대한 포괄적인 설명도 gpt에게 요구함
- 두 벤치마크에 대해 평가함
- LLaVA-Bench (COCO)
- COCO-Val-2014에서 랜덤하게 30개의 이미지를 뽑음
한 이미지 당 3개의 질문 타입을 생성함 → 90개

- gpt4의 참조 예측을 100%라고 가정했을 때 LLAVA의 응답을 평가한 결과임
- instruction tuning을 하는 것이 성능 개선에 중요함
- 적은 양의 detailed 묘사를 주고 complex reasoning 질문을 주는 것이 성능 개선에 중요함
- 심지어 conversation type에서도 성능 향상이 있음 → 추론 능력이 대화 능력도 보완할 수 있음을 의미함
- LLaVA-Bench (In the wild)
더 어려운 문제와 새로운 도메인에서의 일반화 능력을 평가하기 위해서 다양한 24개의 이미지와 60 문제를 모음(실내, 실외, 밈, 페인팅, 스케치)
llava가 bliip, flamingo보다 더 좋은 성능을 보임
Limitations

- 어려운 LLava-bench(inthewild) 예제 2개
- interesting failure: 딸기와 요거트가 각각 있는 상황에서 딸기맛 요거트가 있는가?라는 질문에 llava가 yes라고 대답함→ 이미지를 bag of patches로 인식하고, 이미지의 복잡한 semantic에 대해서는 이해하지 못함
- LLaVA-Bench (COCO)
5.2 ScienceQA
- 21k의 멀티모달 multiple choice questions로 이루어져 있음
베이스라인 모델: GPT-3.5 (CoT 있는 버전 없는 버전 둘다), mm-CoT(현재 이 데이터셋의 sota)
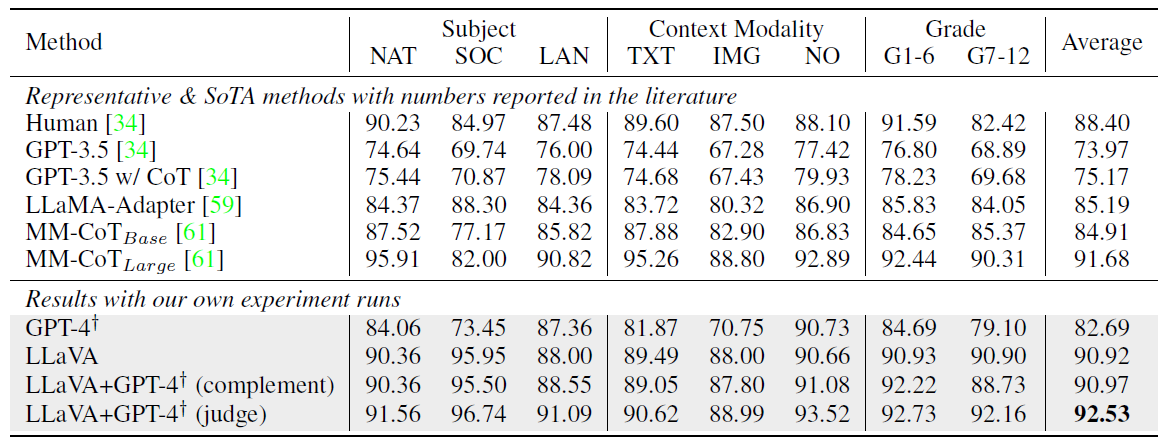
- LLAVA - 비주얼 피처를 마지막 layer 전에 사용, 먼저 reason을 예측한 후 답하라고 함, 12 에폭 학습
*모델이 물체의 뒷모습을 보기 위해 검색 or 유추해서 정보를 얻어내기
Conclusion
- visual instruction tuning의 효과를 입증함
- language-image instruction following data를 만드는 자동 파이프라인을 제시함
- 그걸 따라 만들어진 데이터로 학습한 LLAVA는 복잡한 비주얼 문제를 풀 때 인간의 의도를 잘 따라서 품
- ScienceQA에는 sota 달성, 멀티모달 챗 데이터로 finetuning했을때도 좋은 성능을 보임
- multimodal instruction-following 능력을 평가하는 첫번째 벤치마크를 제시함
내 맘대로 정리


This post is licensed under CC BY 4.0 by the author.