EmoVIT: Revolutionizing Emotion Insights with Visual Instruction Tuning
CVPR 2024
https://github.com/aimmemotion/EmoVIT
Abstract
- Visual instruction tuning - task-specific instruction을 통해 사전학습된 언어 모델을 fine-tuning
- 여러 nlp task에서는 높은 zero-shot 능력을 보여주었지만, visual emotion understanding에서는 아직 탐구되지 않았음
- 본 연구에서는 감정 문맥과 관련한 여러 instruction을 이해하고 따르는 모델의 능력을 향상시키고자 함
- visual emotion recognition에 중요한 key visual clues를 확인함
- emotion visual instruction 데이터를 모으는 파이프라인을 구축함
- InstructBLIP을 기반으로 한 모델 구조 - LLM의 능력을 잘 가져옴
Introduction
- visual emotion recognition은 중요함 - technical challenge일뿐만 아니라 더욱 효율적이고 자연스러운 HCI를 가능하게 함
- 최근 foundation vision 모델을 개발하려는 움직임(flamingo, llava, blip2)
이 모델들은 어려운 open-world 챌린지는 잘 수행하지만, emotion perception에는 취약함
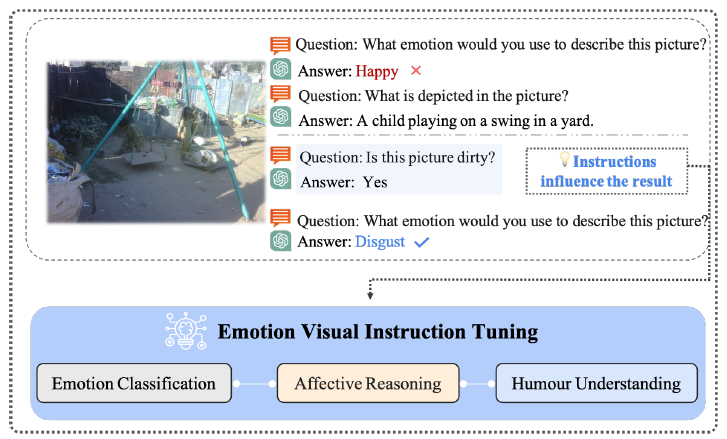
- 그냥 emotion question을 주면 틀린 답을 말하지만, 수정된 instruction을 주면 잘 대답함
- 본 연구는 현재 vision 모델의 최대치의 능력을 끌어오기 위해서 instruction tuning을 기반으로 한 방법을 제시함
- 본 연구는 감정 문맥과 관련한 여러 instruction을 이해하고 따르는 모델의 능력을 향상시키고자 함
- 모델이 지시를 잘 따르는 능력을 finetuning함 → 감정적인 내용을 해석하고 응답할 수 있게 함
- 기존에 모델에 존재하는 지식을 끌어와서 emotion-specific한 모델 구조에 대한 필요성이 없다
- visual emotion recognition에 instruction tuning을 할 때 생기는 challenges,,,
- instruction 데이터의 부재 → GPT-4로 visual emotion recognition에 대해 self로 생성하는 데이터 생성 파이프라인을 구축함
- 추가 challenge: output patterns과 스타일과 같이 surface-level의 특징에 중점을 두는 task에서는 비판을 받아옴(?)
- 이 문제를 해결하고 또 instruction 데이터의 다양성과 창의성을 개선하기 위해서, 우리의 데이터셋은 어려운 추론을 요구하는 instruction을 포함함
- 밝기, 색조 등 visual cues를 포함해서 더 풍부해졌음
- → 모델이 더욱 정확하게 visual 감정을 이해하고 해석하도록 함
- 데이터를 구축한 후에, InstructionBLIP에 기반한 모델 EmoVIT를 제안함
- emotion-centric하고 instruction-aware한 모듈을 포함함 → LLM이 emotion instruction의 뉘앙스를 흡수할 수 있도록 하는 역할
- 본 연구는 패러다임 전환을 예고 - visual emotion understanding에 instruction기반의 학습을 할 때 explicit한 학습 데이터에 덜 의존함
- 기존에 필요하던 데이터 양의 50%만으로도 기존 방법들보다 더 성능을 높임
- Contribution
- emotion comprehension에 Visual instruction을 접목해서 emotion visual instruction tuning라는 개념을 제시함
- visual emotion recognition 자체의 특성을 고려한 GPT가 보조하는 새로운 데이터 구축 파이프라인을 제시함
- InstructionBLIP에 기반한 EmoVIT 구조는 LLM의 능력을 이용해서 여러 emotion task에서 높은 성능을 보임
Related Work
- Visual emotion recognition
- emotion feature learning, emotion dataset 제시 등 기존 연구들이 존재
- GPT와 같은 멀티모달 모델의 등장으로, visual-language 인식은 개선되었지만 emotion recognition은 아직 unexplored area임
- Visual instruction tuning
- instruction tuning은 모델을 자연어 형태의 instruction을 따르도록 모델을 학습시키는 것이 목적임 + 새로운 task에 대한 일반화 능력 높이기
- FLAN / visual 입력을 다루는 BLIP2, LLaVA
- InstructBLIP은 instruction-aware visual feature extraction과 q-former를 사용함
- visual emotion instruction tuning은 emotion instruction 데이터를 만드는 벤치마크나 가이드라인이 없음
Method
3.1. Preliminary of Visual instruction tuning
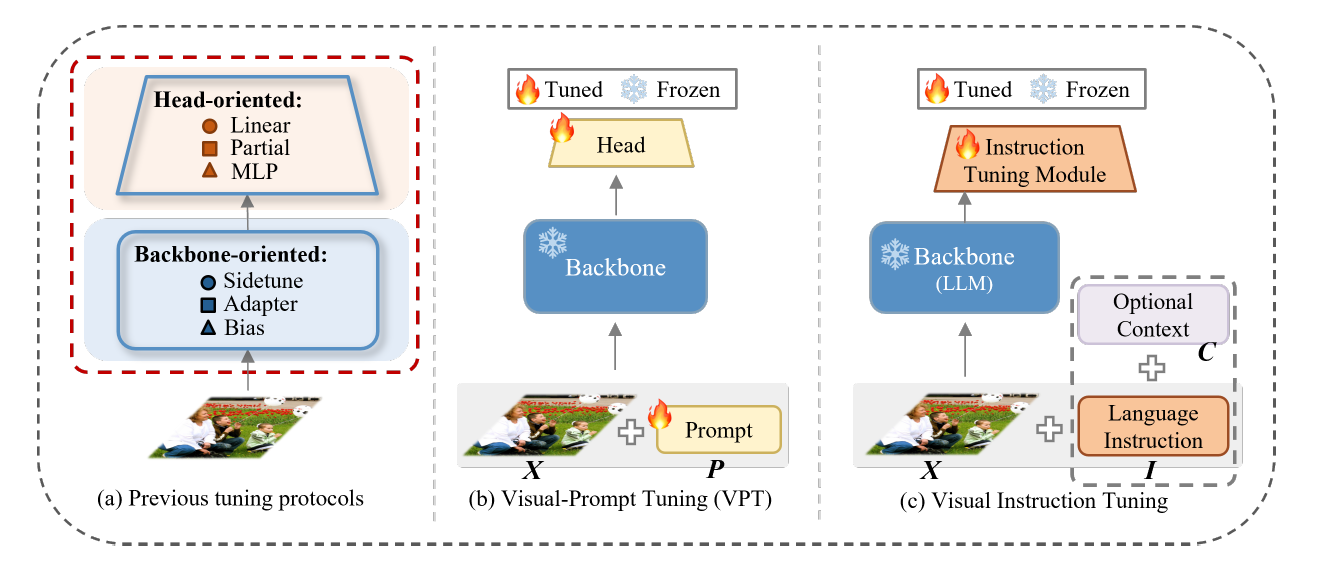
- Full fine-tuning
- end-to-end로 학습하는 방법 → 가장 효과적임
- 백본 파라미터의 전체를 저장해야 하기 때문에 저장과 배포의 문제가 있음
- Visual Prompt Tuning
- full fine-tuning의 효율적인 대체재
- 백본 모델은 frozen상태로 두고, 입력 공간에서 학습할 수 있는 파라미터의 최소 부분을 활용함
- 작은 파라미터 세트를 사용하여 LLM을 최적화하는 데 중점
- Visual instruction tuning
- 모델의 instruction 이해도를 높이는 것, instruction을 따르게 하는 것이 목적임 → 특정 도메인에서의 모델의 문제점을 해결하기 위함
- instruction - 모델의 결과가 특정한 답변 특징을 가지고 있으며, 도메인과 관련된 지식을 가지고 있게끔 함
효율적인 방법임 - LLM이 과도한 재학습 없이 특정 도메인에 adapt할 수 있음
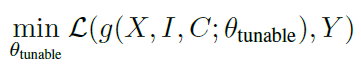
- C = 단순한 raw 데이터는 아니고 descriptive or directive 정보를 포함함, 필수적임
3.2. GPT-assisted Emotion Visual Instruction Data Generation
- 기존 방법들은 여러 데이터셋 별 task 별 일관된 template기반의 instruction을 사용함
- 모델이 각 이미지의 고유한 특징을 적절하게 capture할 수 없음
- 특히 이런 방식의 접근은 모호한 감정 카테고리에 대한 미묘한 인식과 차이를 잘 담아낼 수 없음
- 아직 emotion visual instruction tuning에 대한 벤치마크나 가이드라인이 없음
- llava와 같이 machine-generated instructions에 기반하여, 본 연구는 기존의 LLM을 emotion instruction 데이터 만드는데 사용하기로 함
⇒ instance-wise하고 LLM-assisted visual emotion instruction data pipeline
- 데이터 수집에 앞서서 어떤 visual clue가 감정을 인식하는데 중요할까?
- 본 연구에서는 감정 해석에 있어 주관성과 애매함을 제거한 새로운 visual instruction data 메커니즘을 제시함
- 넓은 스펙트럼의 감정 특징을 통합함 - low-level attirbutes, mid-level attributes, high-level attributes
- ⇒ 모델이 시각적 감정 단서를 정확하고 포괄적으로 해석하고 이해할 수 있는 능력을 향상시킴
데이터 구축 파이프라인
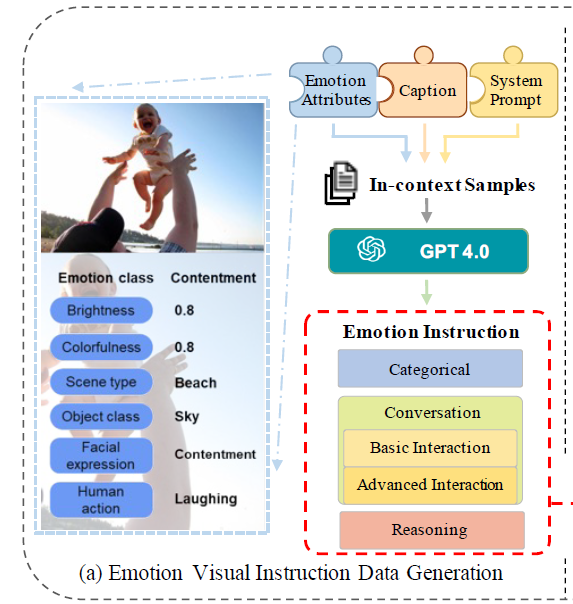
- 이미지 x_img에 대해서 3가지의 이미지와 관련된 문맥이 필요함: 캡션 x_c, 감정 attribute set x_attr, 시스템 프롬프트
- x_attr: emotion class, brightness, colorfulness, scene type, object class, facial expression, human action
- 시스템 프롬프트: gpt가 특정 task 요구사항을 이해하도록 함
- 시드 예시로 쓸 수 있는 몇개의 예시를 사람이 직접 만듦 → gpt-4에 쿼리로 넣어 in-context learning을 할 수 있게끔 함
- 생성된 emotion instruction data의 종류
- categorical, conversation, reasoning

- categorical, conversation, reasoning
- 이미지 x_img에 대해서 3가지의 이미지와 관련된 문맥이 필요함: 캡션 x_c, 감정 attribute set x_attr, 시스템 프롬프트
- 이렇게 데이터를 구축하는 방법은 simple에서 complex로 가는 점진적인 방법을 취함
- categorical
- emotion class를 구조화 시킨 형태
- 데이터의 foundational한 부분
- conversation
- 감정적인 특성에 초점을 둔 대화를 함
- basic: 간단하고 직관적인 특징
- advanced: 어렵고 철학적인 대화
- 감정적인 특성에 초점을 둔 대화를 함
- reasoning
- 단순한 시각적인 내용을 넘어 깊이 있는 추론을 요구하는 질문을 함
- 대화의 신뢰성과 구조를 강화하기 위해, 논리적 추론 단계와 함께 세부적인 예시를 포함
- categorical
3.3. Emotion visual instruction tuning
- 앞서 구축한 데이터로, 우리의 목적은 기존의 visual instruction tuning 모델을 개선하는 것 → LLM의 가지고 있는 지식을 감정을 이해하는 도메인에 align시키는 것
InstructionBLIP에 기초한 EmoVIT
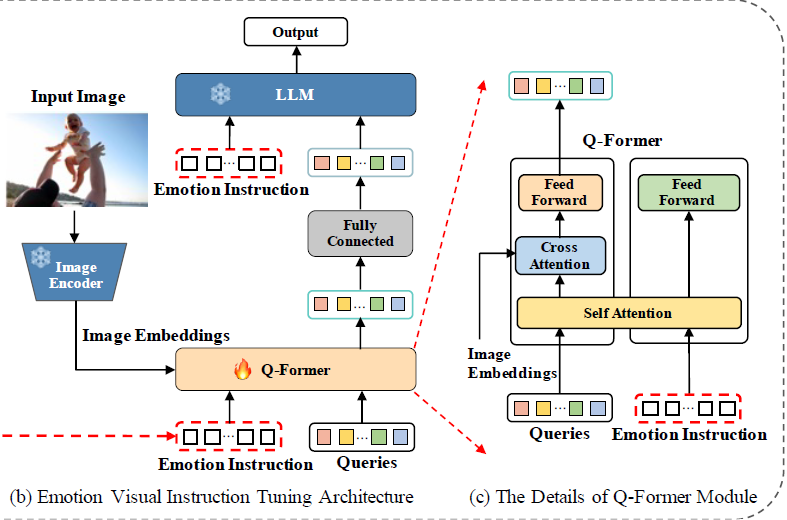
- instruction-aware q-former 모듈 - emotion-centric instructional task에 이 모듈을 이용함
- 입력: emotion instruction token, query, image 임베딩
- 이미지 임베딩은 고정된 이미지 인코더로부터 나옴
- 학습가능한 쿼리는 q-former로부터 나옴 - q-former가 시각적 정보와 instruction, query를 통합하는 역할
- cross-entropy loss
- instruction-aware q-former 모듈 - emotion-centric instructional task에 이 모듈을 이용함
본 연구에서 제안한 방법으로 만든 데이터는 instructblip외의 다른 visual instruction tuning 모델들에도 적용 가능함 - llava가 이 데이터로 학습했을 때 성능 대폭 개선
### 4. Experimental Results
### 4.1. Implementation details
- lavis library 사용
- pre-trained instructblip을 fine-tuning, q-former만 fine-tuning함
Held-in Pretraining
- hold-out : train/test로 데이터를 나누어서 학습에는 train set, 평가에는 test set을 사용
- held-in을 사전학습에 사용하고, held-out을 평가에 사용함
- Emoset이 각 이미지에 emotion attribute가 폭넓게 달려있기 때문에, held-in 사전학습 단계에서 주요 소스로 사용됨
- 다양한 평가를 위해서, 다양한 데이터셋의 테스트셋으로 held-out 평가를 진행함
- 이미지 캡셔닝 : BLIP2, emotion instruction 데이터 구축: GPT-4 API
- 총 51,200 이미지에 대한 instruction 데이터 구축
### 4.2. Held-out Evaluation
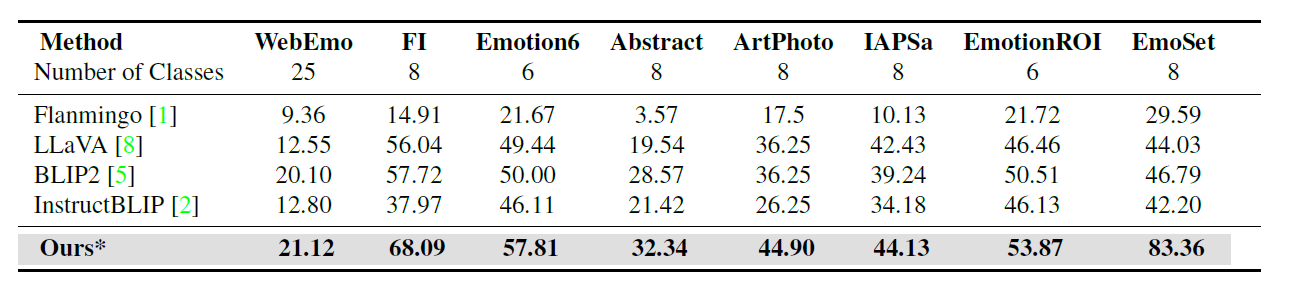
- 우리가 생성한 emotion visual instruction 데이터가 효과적임
Effectiveness of our propsed emotion visual instruction data
- 새로운 이 emotion visual instruction 데이터의 일반화 가능성 평가
InstructBLIP외에 다른 모델에도 똑같이 이 데이터가 적용될 수 있는지 확인 → LLaVA 추가로 확인
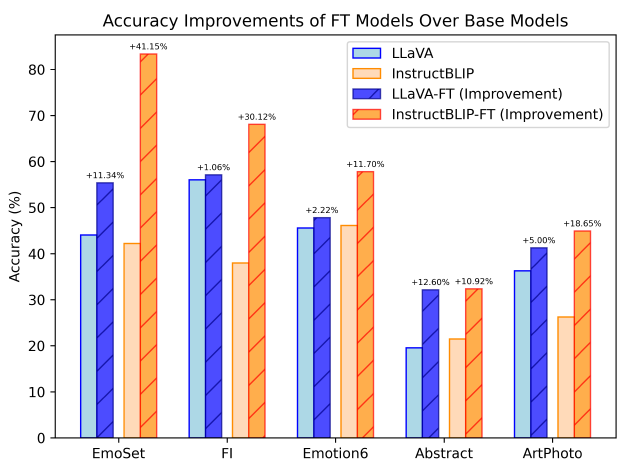
- llava도 동일하게 fine-tuning했더니 오름(당연한거 아닌가..?;;)
- InstructionBLIP의 개선 폭이 더 큰데, instruction-aware q-former 모듈 때문일 것
### 4.3. Effectiveness of Different Instruction Data
4.3.1. Ablation study of different instruction data
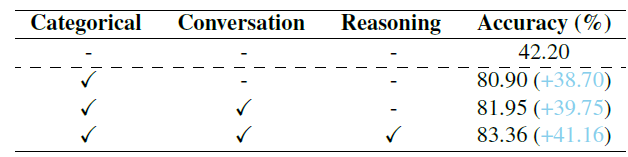
- 데이터 타입을 달리해서 실험
- Emoset test set, accuracy
- categorical, conversation, reasoning 데이터 타입을 순차적으로 추가하면서 성능이 점차 오름
4.3.2. Instruction Sensitivity
- instruction phrase의 자그마한 변동이 있을때 일관된 결과를 보이는지, stability에 대한 평가
- Sensitivity evaluation metric 사용: 모델의 fidelity를 평가함
2개의 내용적으로는 비슷한 instruction을 입력 프롬프트로 사용함
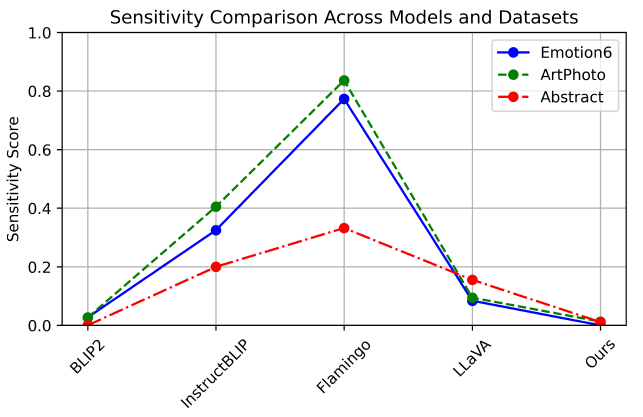
- blip이랑 ours가 sensitivity 점수가 낮음 → stability가 높은 것
### 4.4. Robustness
- 현재 감정 인식 데이터셋이 category imbalance와 labeling bias의 문제가 있음
- 여러 학습 방법들의 일반화 가능성에 대한 평가
- 동일한 객체나 장면과 관련된 정교한 감정을 인식하는 데 특히 적합한 데이터셋인 UnBiasedEmo 테스트셋을 사용

4.4.1 Affective reasoning
- 애매모호하고 주관적인 감정 인식 task에서는 해석가능한 모델이 필요함
- 인지적인 프로세스를 밝히고 그래서 더 신뢰할 수 있음


- 이렇게 예측한 이유에 대해서도 설명가능 - 애매한 감정 카테고리에 대해서도 모델 결정을 설명할 수 있음
- lavis library 사용
4.5. Scaling Law
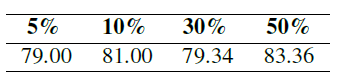
- 데이터 양의 비율 차이에 따른 결과
- 데이터 많아질 수록 성능이 더 좋음
4.6. Humor Caption generation
- humor에 대한 이해는 감정 이해와도 긴밀하게 연결되어 있음
- 학습된 모델을 그대로 캡션 생성에 사용함
- OxfordTVG-HIC 데이터셋 중 50개의 이미지를 선정, 캡션 생성
- 30명의 참가자들중 60%이 모델이 생성한 캡션이 더 재미있다고 고름
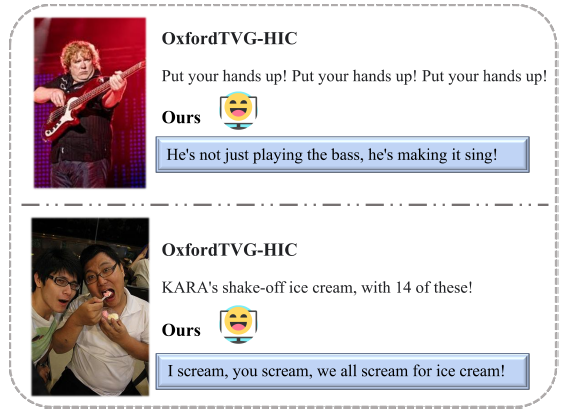
5. Conclusion
- emotion visual instruction 데이터를 생성하는 GPT-assisted 파이프라인을 제시함
- EmoVIT는 emotion-specific instructions를 사용함 / LLM의 좋은 성능을 이용함
- emotion classification, affective reasoning, humor understanding에서 효과를 입증함