ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding
CVPR 2024 / Authors from salesforce, stanford u, pennsylvania u, texas at austin u
https://github.com/salesforce/ULIP
Abstract
- multimodal pretraining의 발전으로 3d representation learning의 성능이 올라감 → multimodal 피처를 정렬: 3d shape, 이미지, 텍스트
- [단점] 3d 데이터에 맞는 텍스트 설명을 수집하는 과정이 비효율적, 확장성이 부족함, 언어 설명의 다양성도 낮음
- 이를 해결하기 위한 ULIP-2
- 3D 데이터만 입력으로 사용함 - 사람이 주석을 달 필요 없음!
- 대규모 멀티모달 모델을 활용해서 3D의 설명 (텍스트)를 생성하도록 함
- 다양한 장면, 구조, 사용 목적을 포함하는 풍부한 설명 생성 가능
- 3D, 이미지, 텍스트의 3가지 모달리티를 동시에 정렬
- 백본을 확장해서 멀티모달 표현 학습 성능을 높임
- 학습 데이터: Objaverse, shapenet
- 학습 과정에서 3d point cloud, 이미지, 텍스트로 구성된 학습 데이터를 자동으로 생성해서 사용함
- 결과 - 여러 downstream task에서 큰 효과를 보임
- zero shot 3d classification, finetuning 3d classification, 3d captioning
- 멀티모달 3d representation learning의 새로운 패러다임을 제시함 - 수동 주석을 달 필요가 없어짐, 기존 방법 대비 성능 향상
Introduction
- 3d visual understanding의 최근 관심 증가
- ar/vr, 자율주행, 로보틱스 등.. 활용 분야 많음
- 하지만 3d 데이터를 수집하고 주석을 다는 과정은 비용이 크고 매우 많은 labor가 들어감
- 이를 해결하기 위해서 이미지/텍스트와 같이 데이터가 많이 존재하는 다른 모달리티를 supervision 신호로 활용해서 3d 표현을 학습하는 방식을 시도하고 있음
- 장점
- 3d 표현 학습 성능 향상
- 3d/이미지/텍스트로 이루어진 풍부한 멀티모달 표현 능력이 생김
- 3d의 대규모 + 정밀한 주석에 대한 의존도를 낮춤
💡 멀티모달 학습은 기존 3d only 학습 방식에 비해서 더 좋은 성능을 보여주며, dense annotation에 대한 문제를 어느정도 완화해왔음
- 단점
- 3d와 연결된 텍스트 정보를 대규모로 확보하기 어려움
- 기존에는 ….
- 3d 데이터의 카테고리 이름을 텍스트로 사용
- 메타데이터에서 가져온 짧은 한줄 설명을 텍스트로 사용
- 이 방식의 문제점?
- 확장 불가능.. → 직접 사람이 하나하나 만들어야 해서 대규모 데이터셋으로 확장하기 어려움
- 정보 부족 → 3d 객체의 형태, 구조, 사용 방식, 질감 등 다른 중요한 정보를 반영하지 못함
- 다양성 부족 & 노이즈 존재 → 표현이 너무 단순하거나, 중복되고, 객체 특성을 충분히 담아내지 못함
- 대규모로 수집 가능하고, 객체 특성을 풍부하게 반영하고, 사람 labor에 대한 의존도가 없는 방식으로 3d에 대한 텍스트 데이터를 생성할 수 있는 새로운 접근이 요구됌
- 3d 데이터에 대한 텍스트를 얻고 사용하는 “최적의” 방식은 아직 불분명함
- 잘 훈련된 annotator가 3d 객체에 대해서 디테일한 텍스트를 만들어낼 수 있지만, 이 방법은 비용이 많이 들고 scalability가 부족함.
- 3d 객체에 대응되는 언어 모달리티가 정확히 어떤 형태여야 하는지도 명확히 정의 x
- 우리는 다음과 같은 관점을 제안함
- “3d 객체의 적절한 <이미지> 모달리티란 무엇인가?”
- 하나의 객체를 다양한 뷰포인트에서 렌더링하고, 그 이미지들을 모으면, 3d 객체가 가진 정보 대부분을 포함하게 됌
💡 여러 각도에서 찍힌 이미지들의 집합 = 3d 객체의 의미적 정보 전체를 근사적으로 담는 것
⇒ 텍스트에 대해 대입해보면,
- 3d 객체를 여러 시점에서 “언어적으로 묘사”한 후, 그 설명을 모은 집합은 해당 3d 객체가 언어적으로 표현할 수 있는 정보를 거의 다 담은 것일 것
- “3d 객체의 적절한 <이미지> 모달리티란 무엇인가?”
- 구현 방식
- 계산 효율을 위해 고정된 관점의 소수 뷰만 샘플링을 해서 사용함
- 과정
- 3d 객체를 여러 각도에서 렌더링해서 이미지 생성
- 각 이미지에 대해서 대규모 멀티모달 모델로 설명을 자동 생성
- 설명들을 모아서 3d의 풍부한 텍스트 모달리티 완성
- 장점
- 3d 데이터만 입력으로 사용함
- 사람의 수작업 annotation이 필요 x
- 대규모 확장 가능
- 다양하고 정밀한 설명을 확보함
- 대규모 멀티모달 모델의 지식이 언어 설명으로 distill함
- 이렇게 얻은 텍스트 데이터는 멀티모달 3d 표현 학습의 성능과 일반화 능력을 크게 끌어올릴 것
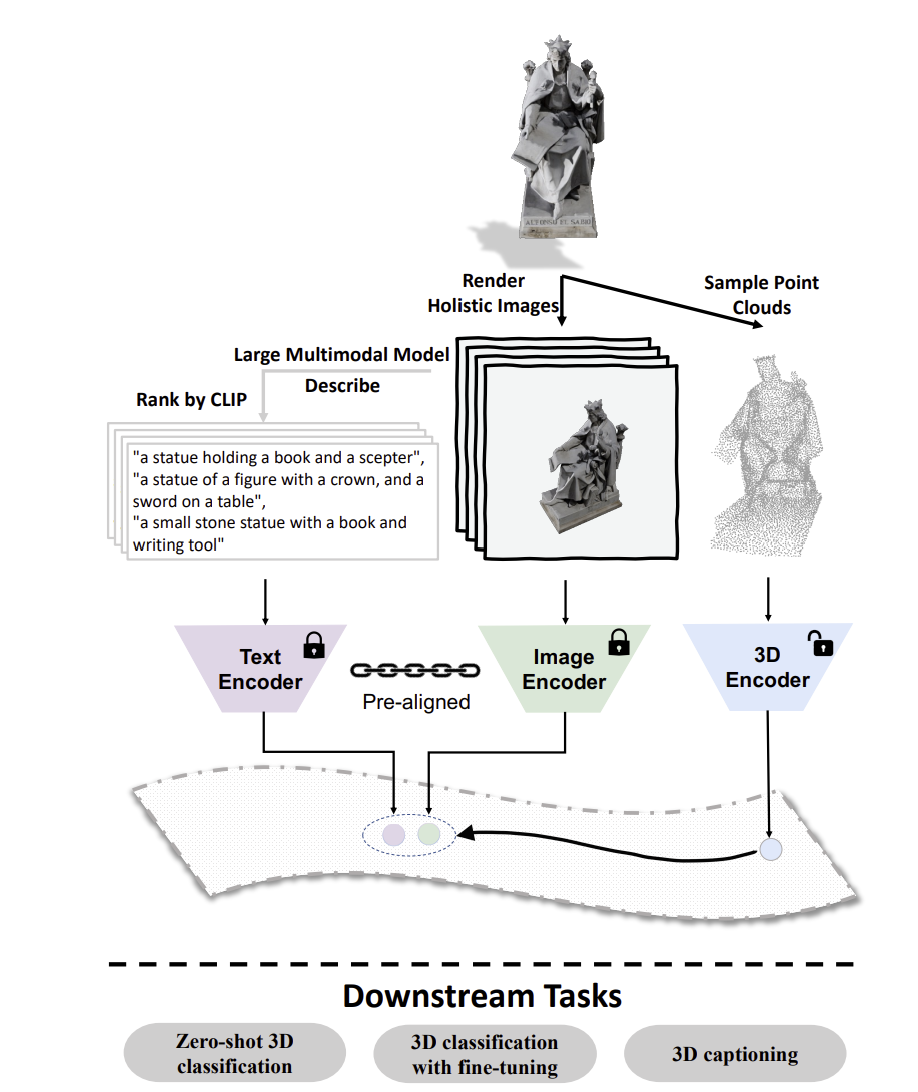
- ULIP-2
- 핵심 목표
- 확장 가능하고 풍부한 멀티모달 3D 데이터 <자동 생성="">
- 멀티모달 정렬을 강하게 학습하는 효율적인-training 아키텍처="" 구축=""> 1. **데이터 자동 생성 파이프라인**
- 3d 모달리티 생성: pc를 추출함
- 이미지 모달리티 생성
- 사전 정의된 각도에서 렌더링 3. 텍스트 모달리티 생성
- 각 렌더링된 이미지에 대해서 텍스트를 mllm을 통해 자동 생성
- 사전 학습 과정
- 3가지 모달리티 데이터를 효율적인 멀티모달 사전학습 구조로 정렬함
- 이를 통해 모델은 각 모달리티 간의 의미적 대응관계를 학습하고, 종합적이고 견고한 멀티모달 3d 표현을 학습함
- 효과
- 확장 가능한 멀티모달 데이터 생성
- 풍부하고 세밀한 텍스트 데이터 확보
- 효율적인 멀티모달 사전학습으로 강력한 3d 표현 획득
- 핵심 목표
- ULIP → ULIP-2 무엇이 개선되었는가
- 사람의 수작업 없이 멀티모달 데이터를 자동 생성하는 패러다임 제안
- 이를 기반으로 대규모 3D 데이터셋 확장
- 동일한 데이터셋에 대해서 학습을 했을 때도 ULIP 대비 모든 다운스트림 task에 대해서 큰 폭의 성능 향상
- contribution
- “사람 annotation 없이” 확장 가능한 멀티모달 3d 사전 학습
- 멀티모달 표현 학습 성능의 큰 폭 개선
- 대규모 3d 모달 데이터셋 공개: ulip-objaverse, ulip-shapenet
Method
3.1. Preliminary: ULIP
- 멀티모달 사전학습을 통해 3개 모달리티를 하나의 공통 표현 공간에서 정렬시키는 프레임워크
- triplet
- 3d: 3d의 point cloud를 추출해 3d encoder를 passing한 결과
- 이미지: 렌더링한 결과를 이미지 encoder로 추출한 결과
- text: 카테고리 이름, 객체 속성, 메타 데이터 등을 프롬프트 기반으로 문장으로 만듦 → text encoder로 passing 결과
- 메타데이터에 semantic적으로 의미 없는 정보도 포함됨..
- 모델: SLIP (이미지-text 표현 공간) 모델 사용 (clip 변형 모델임)
- 3d 특징을 pretrained된 표현 공간으로 정렬하도록 학습함
- 3d encoder의 결과 피처가 slip의 공통 멀티모달 피처 공간과 일치하도록 유도함
- ULIP-2도 목적은 동일함
- 대규모 생성 방식과 확장성 개선이 차별점
3.2. Scalable Triplet Creation
- 3d 객체를 입력으로 넣으면, 트리플렛 데이터를 자동 생성
- 3d, 이미지는 기존과 동일
- 텍스트: 각각의 렌더링된 이미지에 대해서 BLIP-2를 이용해서 설명 문장들을 자동 생성
- 만들어진 문장들은 CLIP 유사도 기준으로 랭킹
- 유사도가 가장 높은 TOP-1 문장을 이미지 설명으로 최종 사용함
장점: 사람이 텍스트 데이터 만들 필요가 없음! 그래서 대규모 데이터에 바로 확장 가능함
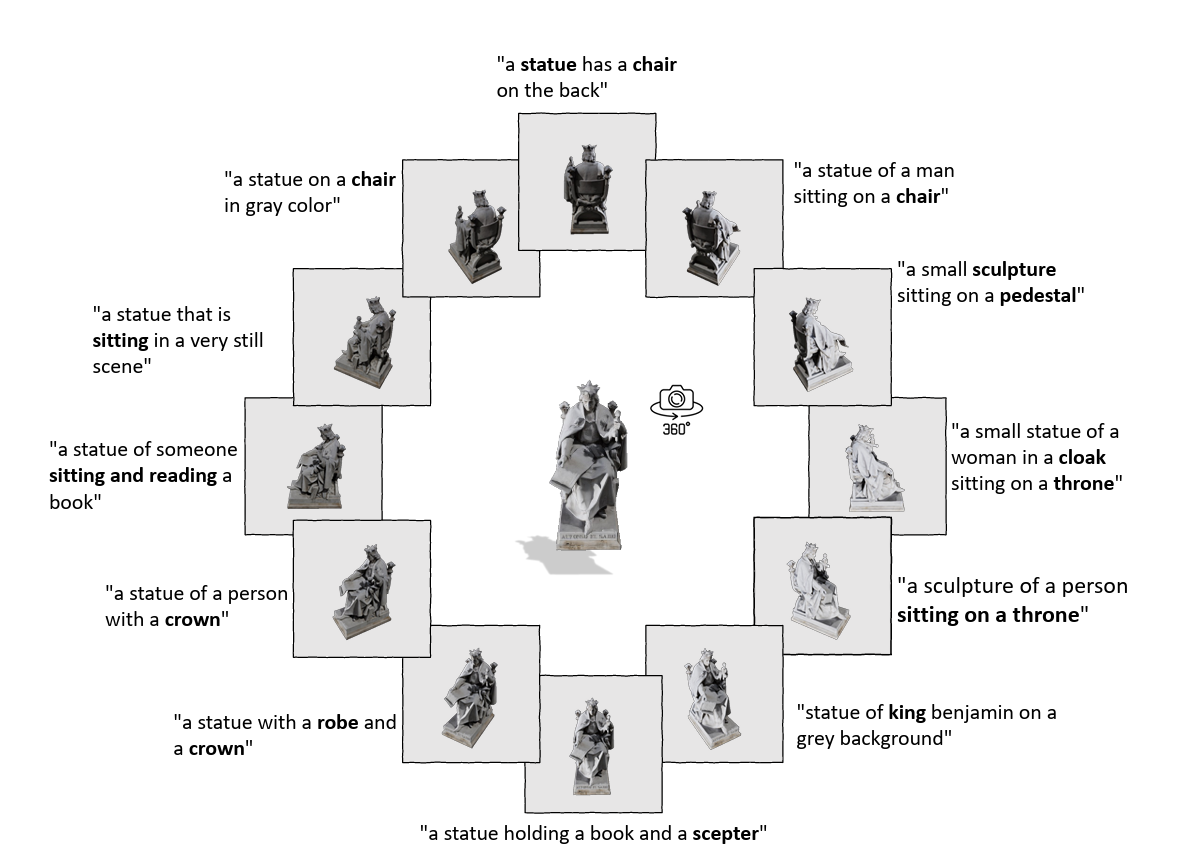
3.3. Tri-modal pre-training
- 어떻게 3가지 모달리티를 공통 임베딩 공간으로 정렬할 것인가?
- text, image는 서로 이미 정렬됨
- 목적은 3d 인코더를 새로 학습 → 3d 특징도 동일한 공간에 함께 정렬하는 것
- 학습 대상: only 🔥3d encoder, ❄️image/text encoder는 freeze
- loss
3D-image contrastive loss
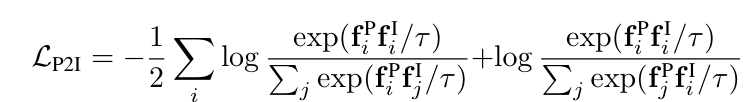
- 정답 pair (3d-image) 간의 유사도는 높게, 오답 pair (3d anchor - image negative sample)과의 유사도는 낮아지도록 학습
- 3D-text contrastive loss
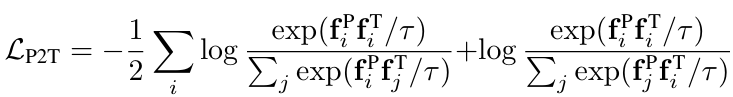
- 마찬가지로,
- 정답 pair (3d-text) 간의 유사도는 높게, 오답 pair (3d-text negative sample)과의 유사도는 낮아지도록 학습
최종 loss
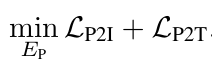
- loss가 최소화되도록 3d encoder E_p를 학습
- 3d 객체 하나를 anchor로 두고, triplet 내의 이미지/텍스트 피처와는 가까워지도록, 다른 객체의 이미지/텍스트 피처와는 멀어지도록 contrastive learning 진행
3.4. Scaling Up the 3D Multimodal Learning
- RQ: ulip2에서 이미지/텍스트 인코더를 더 강력한 모델로 교체했을 때 어떤 이점이 있나?
- ulip에서는 ViT-B 기반의 비교적 작은 인코더를 사용함
- ulip2에서는 ViT-g/14 등 더 큰 모델을 사용해서 성능 향상 기대
- vision-language 백본 모델만 업그레이드, 나머지 훈련 파이프라인은 동일
- task: zero-shot classification
- data: modelnet40, objaverse-LVIS
Experiments
4.1. ULIP-Objaverse Triplets and ULIP-ShapeNet Triplets Creation
- 학습에 사용한 트리플렛 데이터 생성

- ULIP-Objaverse
- objaverse 1.0 버전을 대상으로 / 약 80만개
- blender를 이용해서 12개의 이미지를 렌더링 (360도를 12등분한 각도에서 촬영)
- 하나의 이미지에 대해서 BLIP-2-opt6.7B 모델로 10개의 문장을 생성
- CLIP-ViT-Large 모델로 이미지–텍스트 유사도 기준 랭킹
- top 1 문장을 텍스트 데이터로 사용함
- 3d 포인트 클라우드는 10k, 8k, 2k 포인트 버전을 생성해서 여러 downstream task를 지원함
- ULIP-ShapeNet
- shapenet: 55개 카테고리 / 약 52.5k개
- 30개의 시점에서 rgb 이미지 + depth map을 렌더링함
- 똑같이 텍스트 데이터 생성 - triplet 데이터셋 모두 공개 !
4.2. Downstream Tasks
- 평가 데이터셋: modelnet40, objaverse-lvis, scanobjectnn
- task
- zero-shot 3d classification (입력: 멀티 모달리티)
- 3d 피처와 텍스트 피처의 유사도를 기반으로 가장 유사한 카테고리를 예측값으로 사용
- top1, 5 accuracy
- 멀티모달 정렬을 통해 3D 의미 이해 능력을 잘 갖췄는지 확인
- standard 3d clasification (입력: 단일 모달리티)
- 입력: 3d, 출력: category 이름 (텍스트 피처는 사용 x)
- 3d classification으로 미리 finetuning함
- accuracy, class average accuracy
- 일반 3D 분류 모델로도 쓸모 있는지 확인
- 3d captioning
- CIDEr score
- zero-shot 3d classification (입력: 멀티 모달리티)
- 3d backbone: Point-BERT, PointNeXt
4.3. Comparisons to Baselines
zero-shot 3d classification
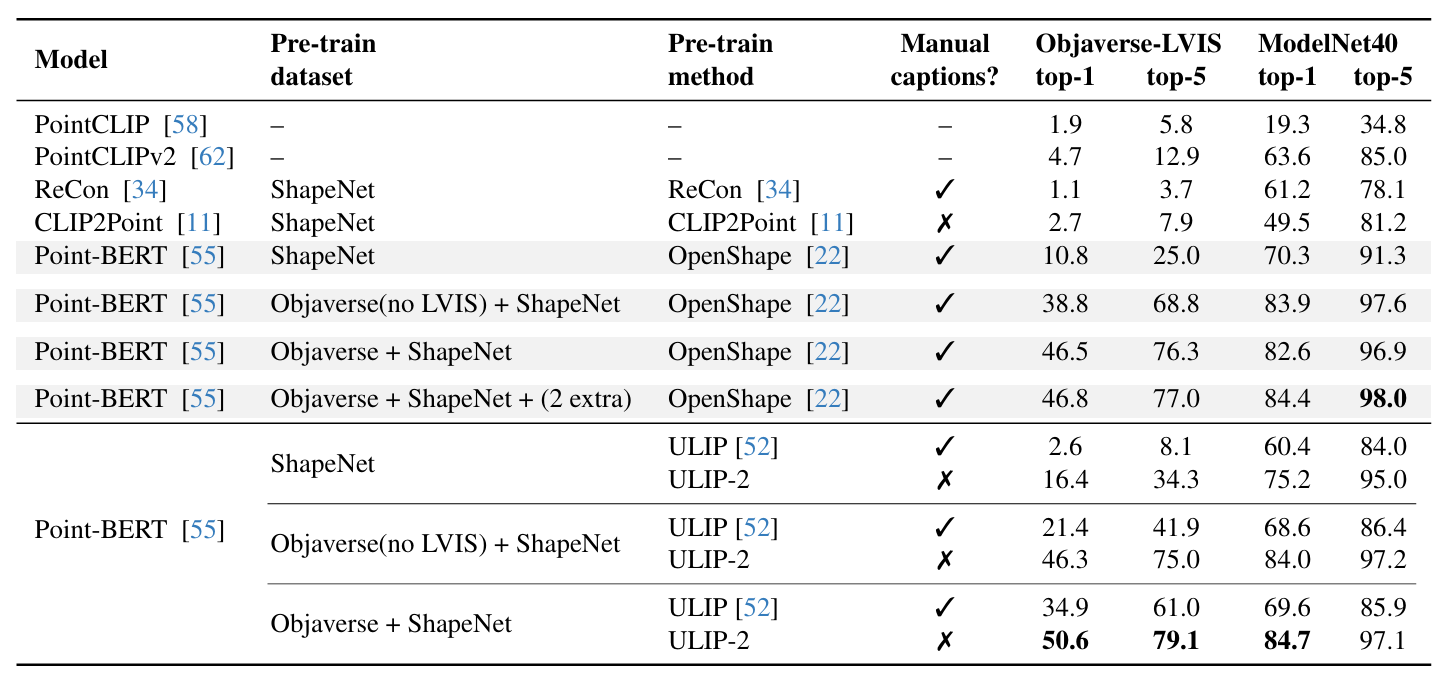
- ulip과 openshape에서 사용한 zero-shot 3d cls 절차를 동일하게 따름
- 비교 대상: 기존 zero-shot 3d
- ulip과의 비교
- 어떤 조합의 데이터셋 학습으로도 ulip과 비교했을 때 큰 폭으로 성능 향상
- sota와의 비교
- openshape보다 objaverse lvis top1 기준 더 좋은 성능 보임
- → 더 복잡한 구조 없이도 기존 sota를 뛰어넘는 zero-shot 3d 분류 성능을 보여줌
standard 3d classification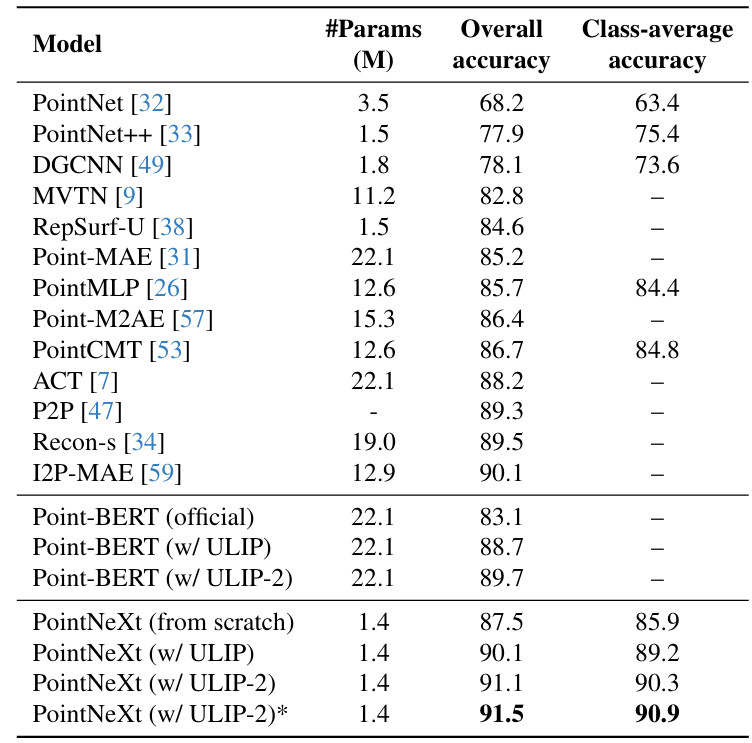
- 데이터셋: scanobjectNN hardest split (난이도 높음)
- Point BERT
- ULIP 없는 버전 대비 +6.6%
- PointNeXt
- ULIP 없는 대비 +4.0
- 아주 작은 파라미터 1.4M로 최고 성능 달성함
→ zero-shot 분류 뿐 아니라 일반 supervised 3d cls에서도 이득임
3d-to-Language Generation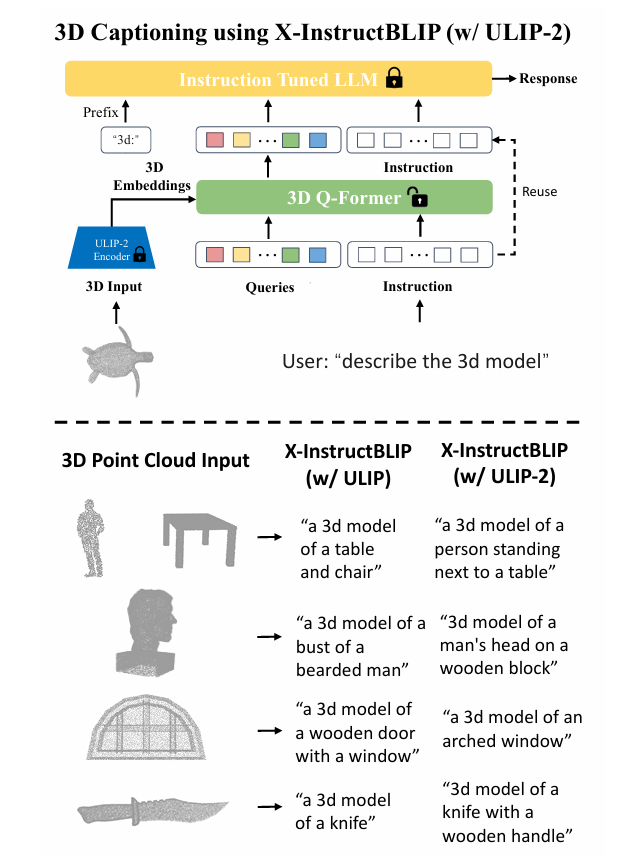
- ulip2로 학습한 3d 인코더를 llm과 결합해서 3d → text 생성함
- 결합 방식: X-InstructBLIP 프레임워크를 사용함 (3d 인코더 + llm)
- point-bert 백본 사용
metric: CIDEr Score (COCO captioning 평가 도구)
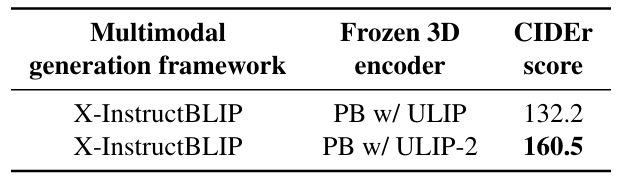
- PB는 Point BERT
- ulip2가 성능 훨씬 좋아짐
- ulip2를 붙인 모델이 만드는 캡션이 더 세부적이고 정확하고 정보량이 많음
→ ULIP2를 사용하면 3D 캡션 생성 능력이 좋아짐!!
Ablation Study
5.1. Ablation on the effect of the generated captions
- BLIP2가 자동 생성한 캡션이 얼마나 중요한 역할을 하는가?
학습 세팅은 모두 동일하게, 텍스트 데이터만 교체해서 실험

- zero-shot modelNet40 분류 성능
- SLIP ViT-B 인코더 사용 (ulip에서 사용함)
→ 자동 생성된 고품질 캡션이 zero-shot 성능 향상에 기여함
5.2. Different Large Multimodal Models
- ULIP2 성능 향상에
캡션이 얼마나 역할을 하는가? 어떤 캡션 생성 모델을 쓰느냐에 따른 성능 차이

→ blip-2가 만들어내는 캡션을 사용했더니 성능 더 좋아짐 / mllm이 발전할수록 3d representation pretraining의 성능도 개선될 여지가 있음
5.3. Number of 2D views per 3d object
- 3d 객체를 더 다양한 시점에서 렌더링해서 캡션을 더 많이 만들면 성능이 좋아지는가?
시점 수를 늘릴수록 zero-shot 분류 성능이 더 좋아지는지
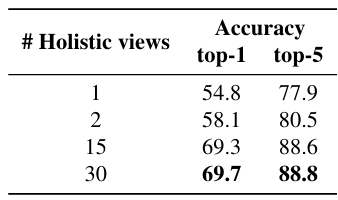
- 뷰 수가 증가할 수록 성능이 개선됨
→ 3d 객체를 다양한 각도에서 묘사할수록 blip-2 캡션이 더 풍부한 시각, 구조, 형상 정보를 제공해서, text-3d 정렬이 더욱 정교해짐
5.4. Top-k CLIP Ranked Captions Per 2D View
한 이미지에 대해 생성된 10개의 캡션 중에서 몇개를 학습에 사용하는 것이 가장 좋은가?

- top-1만 사용하는 것이 성능이 가장 좋음
- 아마도 중복, 불필요한 정보, 묘사 오류가 포함될 확률이 낮기 때문일 것
5.5. Scaling Up the Backbone Models
백본 모델의 크기를 키우면 성능이 얼마나 향상되는가?
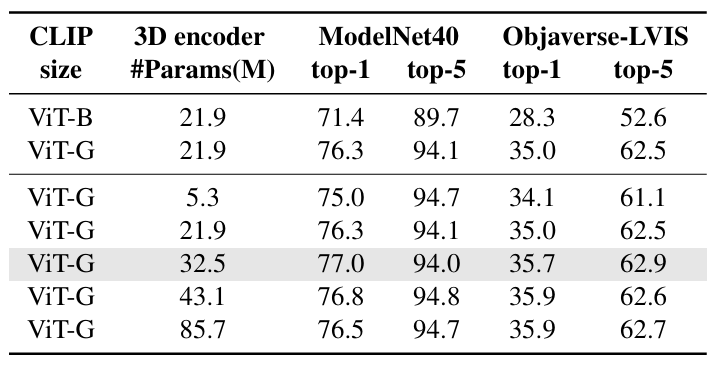
- clip의 경우 더 큰 모델이 더 좋은 성능
- 3d encoder의 경우 32.5m의 크기가 가장 좋은 성능을 보임 (성능/효율 균형 상 최적임)
- 그보다 더 크면 정체
- 대형 CLIP + 중형 3D 백본 조합이 가장 효율적인 구성임!
Conclusion and Discussion
- 멀티모달 3d 표현학습을 위한 새로운 프레임워크로 ULIP-2를 제안함
- mllm을 활용해서 고품질 텍스트 설명을 자동 생성하고, 대규모 3D 사전학습을 확장 가능하게 함
- 사람의 주석이 필요한 확장성 문제 해결 + 모든 downstream task에서 큰 성능 향상
- 대규모 triplet 데이터셋 2개 공개함
Limitations
- 객체 단위로 3d를 학습함, scene 단위는 훨씬 복잡하고 분포도 다름
- 객체 단위 사전 학습이 장면 이해에 그대로 확장될지는 불확실함
- future work
Broader Impact
- 인간 주석 의존도 크게 줄임
- 3d 데이터 활용 비용을 낮추고 연구 속도 향상에 기여
- 부정적 영향: 데이터 라벨링 등의 저숙련 노동 시장 감소 가능성 …
한줄 요약
- ULIP → OpenShape → ULIP-2 순서로 발전
- ULIP은 (text-image-3d) triplet 데이터에서, 수동 작업이 필요했던 text 데이터를 자동 생성해서 확장성을 키웠다는 것에 큰 의의가 있음
openshape과의 공통점/차이점- loss function 동일함
- 3d encoder만 학습, text/image encoder는 freeze한 것도 동일함
- openshape은 text data를 메타 데이터와 자동 생성 데이터를 섞어서 사용함 (매번 랜덤하게 어떤걸 쓸지 선택함)
- openshape은 hard negative mining을 통해서 더 효율적인 학습을 도모함
- 배치 안의 여러 negative 후보 중에서 clip 유사도가 높은 데이터를 hard negative로 선택하는 방식..