Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
https://github.com/Tencent-Hunyuan/Hunyuan3D-2.1
Abstract
- 3D AIGC (AI-generated content)의 응용 분야 다양함
- 많은 모델들이 등장했으나, 여전히 3d 데이터의 수집, 처리, 학습 과정이 복잡해서, 연구자/개발자/디자이너에게만 접근 가능한 영역으로 남아 있음
- Hunyuan 2.1을 소개함 - 데이터 전처리, 모델 학습, 성능 평가
- Hunyuan3D - DiT : 3d shape을 생성
- Hunyuan3D - Paint : 텍스처 합성
Intro
- diffusion 모델의 발전으로 2d 이미지/비디오 생성 분야의 혁신적인 발전
- 하지만 3d 생성은 아직 후발주자임 - 잠재 표현 학습, 기하 구조 정제, 텍스처 합성 등 비교적 기초 기술의 점진적인 개선에 머무르고 있음
- ex. CLAY
- 3D 도메인에는 대규모로 확장 가능한 foundation 모델이 부재함
- 이에 단일 이미지 입력만으로 텍스처가 입혀진 3d 메쉬를 생성할 수 있는 종합적인 3d 생성 Hunyuan3d 2.1을 제안함
- Hunyuan3D-DiT: flow 기반 diffusion 모델, hunyuan3d-shapeVAE를 결합
- Hunyuan3D-Paint: pbr 재질 생성을 위한 multiview diffusion 모델, 멀티 채널 정렬, 시점 일관성을 갖춘 텍스처 생성
- mesh 생성과 텍스처 생성의 2단계 파이프라인
- 여러 벤치마크 모델과 비교, 기하 디테일 보존성, 텍스처-사진 일관성, 인간 선호도에서 모두 우수함을 증명
Data processing
1. dataset collection
- shape generation
- 100k+ textured/untextured 데이터 사용
- public : shapenet, modelnet40, thingi10k, objaverse
- texture synthesis
- 70k+ human annotated high quality 데이터를 필터링해서 사용
- objaverse-xl의 strict curation protocols를 따름
2. data 전처리 for shape generation
normalization
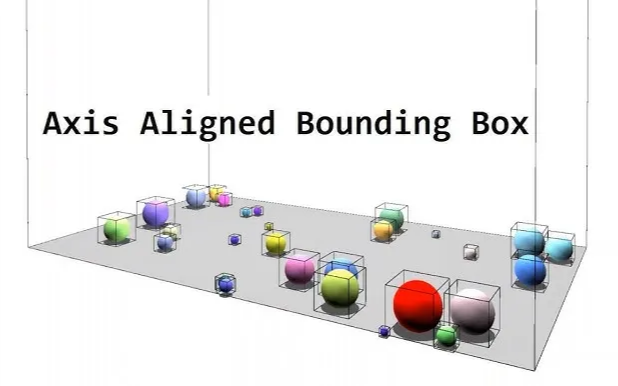
- 목적: 공간 정규화
- 객체들의 크기 차이가 그대로 모델에 입력되면, 모델은 객체의 진짜 구조적인 차이보다 “크기 차이”에 민감하게 반응할 수 있기 때문에 중요함 1. 각 객체의 axis-aligned bounding box (AABB)를 계산함 2. 객체가 원점 (0, 0, 0)을 중심으로 하는 unit cube에 들어가도록 uniform scaling을 함
- 전체 데이터셋에 걸쳐서 일관된 스케일을 확보하되, 각 객체는 본래의 비율을 유지할 수 있게 됌
- 구현
- 포인트클라우드의 중심을 계산
- 모든 점에서 중심점을 빼서 원점으로 align
- 중심에서 가장 먼 점의 유클리드 거리를 계산
- 모든 점에서 최대 유클리드 거리를 나누어서 스케일링함
- 목적: 공간 정규화
- watertight
- igl 라이브러리
- 손상있는 기하구조로부터 SDF를 계산해서 완전히 밀폐된 표면을 생성함 (”watertight”)
- 밀폐형 표면을 watertight라고 부르는듯
- 우선 균일한 3D query grid를 초기화함 (복셀 단위로 grid를 만드는 것과 비슷한듯)
- 쿼리 포인트는 복셀의 중심점으로 보면 되는듯
grid 내부의 각 쿼리 포인트 q에 대해서 sdf 값을 계산함

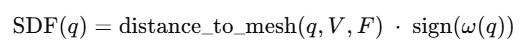
- V, F: 메쉬의 정점, face
- distance_to_mesh: 메쉬 표면까지의 거리
- sign: 점이 표면 내부인지 외부인지 나타냄
- w: 와인딩 넘버 (공간의 내부/외부를 판단하는 값)
- 점 q가 메쉬 내부에 있다면 → 1
- 점 q가 바깥에 있다면 → 0
- sign(ω(q))값은 -1 or 1
- 0 level-set: sdf 값이 0인 모든 점들의 집합
- marching cube를 통해 물체 표면인 영역(0 level-set)을 삼각형 메쉬로 추출함
- sdf를 기반으로 표면을 추출하면, 완전히 닫혀있는 watertight 메쉬가 만들어짐
- sdf sampling
- 모델이 학습할 데이터 만드는 파트 - 공간 전체에서 query point를 뽑음
- 앞에서 만든 marching cube에서 뽑는 거임
- 쿼리 포인트를 선택하는 방법으로 2가지를 사용함
- 표면에 가까운 점들 → 형태의 미세한 표면 디테일을 포착할 수 있음
- 전체 공간에 uniform하게 분포된 점들 → 거시적인 구조를 파악할 수 있음
- 각 점에 대해서 sdf 값을 계산함
- 2중 전략을 사용함으로써 모델이 형태의 세밀한 부분과 전체적인 구조를 모두 균형 있게 학습하도록 해줌
- 모델이 학습할 데이터 만드는 파트 - 공간 전체에서 query point를 뽑음
- surface sampling
- 3d 포인트 샘플링 전략 - 표면에서 point를 뽑음
- 하이브리드 전략
- 균일 샘플링 : 50%
- 기하학적 특징 기반 샘플링: 50%
- 고곡률 영역에 집중함: 날카로운 모서리, 코너, 복잡한 디테일 등..
- 고곡률 영역은 importance sampling을 통해서 찾음
- 결과적으로, 복잡한 부분은 많이 샘플링되고 단순한 평면은 덜 샘플링됨
- condition render
- 입력 조건 이미지를 어떻게 만드는지, 어떻게 렌더링을 다양화하는지
- 150개의 카메라를 균일하게 sphere에 배치함
- 물체의 중심을 원점으로 구 표면 위에 카메라를 배치
- 균일하게 배치 → Hammersley sequence라는 low-discrepancy 점 샘플링 알고리즘
- 매 epoch마다 약간씩 샘플이 달라지게 랜덤 offset을 추가함
- 다양한 각도에서의 시각적 변형을 학습
- FOV (field of view)를 랜덤하게 바꿔줌
- 카메라 시야각을 10~70도 사이에서 랜덤으로 바꿔줌
- 카메라 반지름을 조절해서 물체가 프레임에 잘 맞게 함
- FoV가 작으면(zoom in) 거리를 멀리
- FoV가 크면(zoom out) 거리를 가깝게
3. data 전처리 for texture generation
- texture 합성은 고품질 데이터가 매우 중요함
- objaverse, obj-xl에서 가져온 데이터 중에서 엄격하게 필터링해서 7만개를 얻음
- 카메라 뷰 설정
- 각 객체에 대해서 4개의 elevation 각도에서 렌더링: -20, 0, 20, 랜덤 각도 1개
- 각 elevation마다 24개의 수평 회전 (azimuth)을 선택해서 4 * 24 = 96개의 뷰를 만듦
- 텍스처 맵 종류
- 각 뷰마다 아래의 텍스처를 모두 렌더링함
- 크기 512x512
- albedo, metallic, roughness, HDR or point-light (완전한 pbr)
- 추가적으로 랜덤한 렌더링을 더함
- 더 모델이 robust해지도록
- 카메라 뷰포인트를 랜덤하게 (elevation -30~70)
- 조명도 랜덤하게 (hdr 환경광 p=0.7, point light p=0.3)
Training
Hunyuan3D-Shape
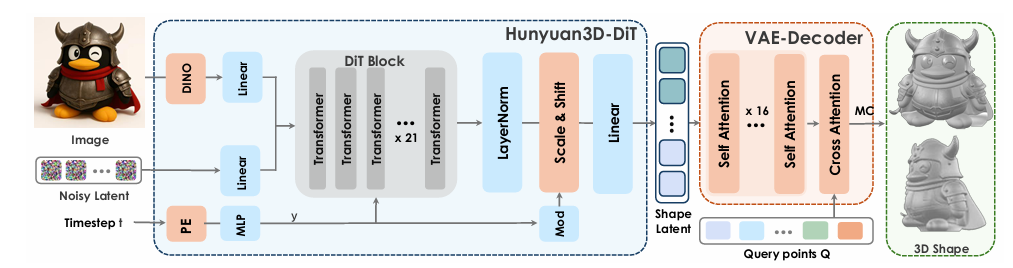
- 두가지 요소: hunyuan3d-shapeVAE, hunyuan3D-DiT
- shapeVAE: 3d 객체 → latent space의 연속적인 토큰 시퀀스로 압축함
- 인코더/디코더
- DiT: latent space 위에서 학습되는 “diffusion 생성 모델”
- 이미지를 입력으로 받아서, 그를 반영하는 3d 객체의 latent token 시퀀스를 예측함
- 입력: 이미지, 출력: latent token
- 조건을 반영한 latent token
- inference 시,
- 사용자가 입력 이미지 넣음
- 이미지 → DiT → latent token → shapeVAE → 3d 객체
Hunyuan3D-ShapeVAE: 3D ↔ latent vector
- vector set 기반 3d 표현 방식 - 3DShape2VecSet, Dora에서 사용한 방법
- transformer 기반 VAE 구조
- 입력: 포인트 클라우드의 x, y, z 좌표 + 각 포인트의 normal vector
- 앞에 전처리 단계의 surface sampling에서 뽑은 point cloud?
인코더 (3D point cloud→ latent vector)
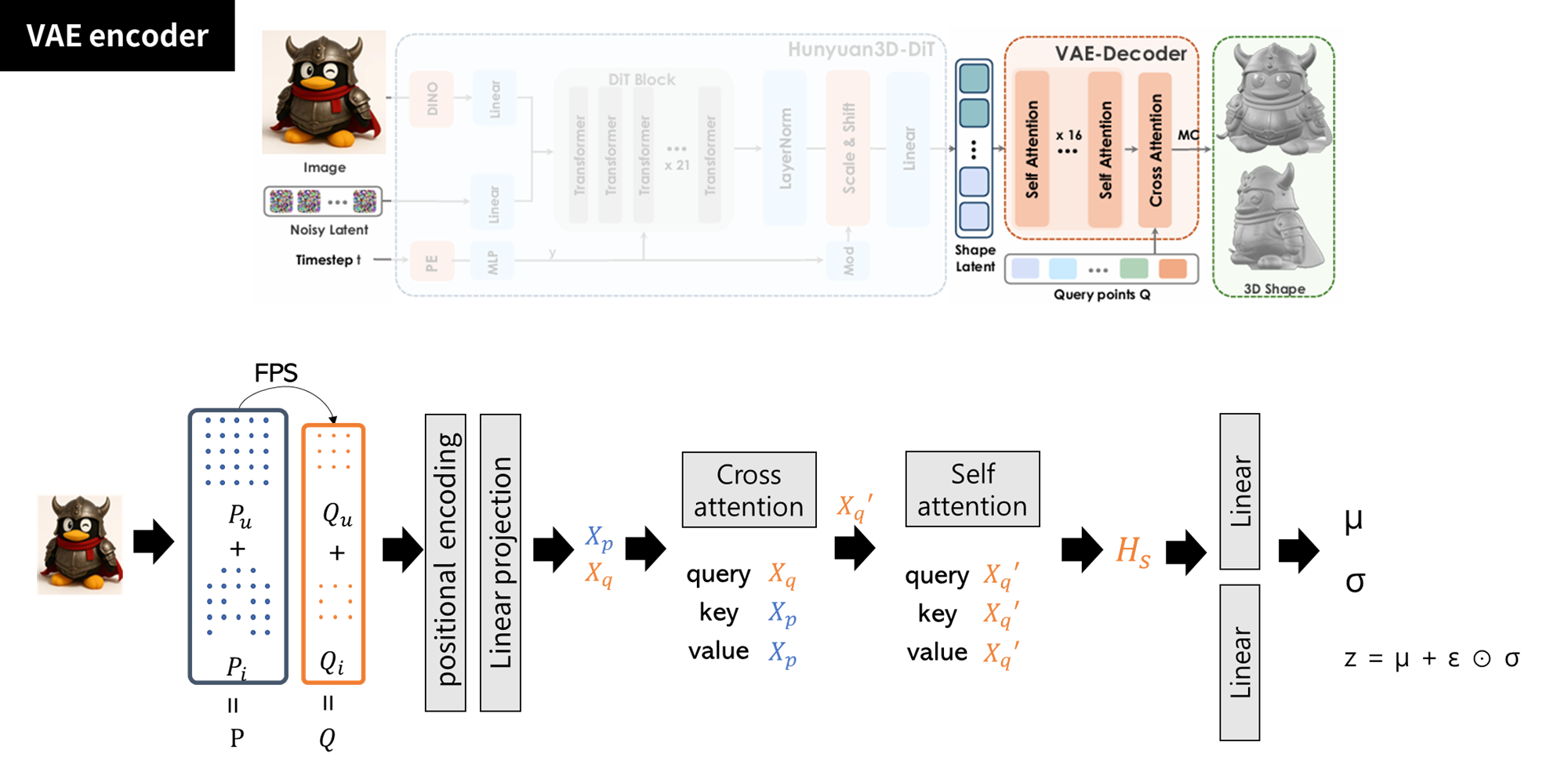
- 포인트 샘플링
- uniform sampled P_u (M개), importance sampled P_i (N개)
- Farthest point sampling을 통해
- P_u → query point Q_u (M’개), P_i → Q_i (N’개)
- 보통 M′ < M, N′ < N
- P = concat(Pu, Pi) → (M + N) points
- “VAE 입력으로 들어가는 표면 포인트”
- → 3d shape의 모든 정보를 담고 있는 많은 양의 포인트들
- 개수가 많아서 attention 비용이 증가함
- Q = concat(Qu, Qi) → (M′ + N′) points
- “Attention에서 query로 사용하는 포인트”
- → 소수의 대표 포인트들
- 개수가 적어서 계산량이 적고, 형상 구조의 핵심을 추출하는데 사용
- q 포인트 하나가 p 전체를 훑고 중요한 정보만 가져오는 역할
- *FPS의 역할: 입력 포인트에서 공간적으로 고르게 떨어진 대표 포인트들을 선택해서 모델이 “균일한” 구조 패턴을 학습하게 함 - P, Q → (positional encoding) → (linear projection) → 임베딩(X_P, X_Q)을 만들고
- P_u → query point Q_u (M’개), P_i → Q_i (N’개)
- attention을 통해 포인트 간 관계 학습 후, 최종 shape representation
- cross attention
- query: 앞서 만든 query point X_q
- key/value: 입력 point cloud X_p
- query 포인트가 전체 포인트를 흡수해서 풍부한 shape feature를 만듦
- self attention
- query/key/value = X_q (q의 임베딩)
- query 포인트 간의 관계 파악, 전체 shape의 구조적 패턴 학습
- latent 분포 추정 (평균, 분산) → latent shape embedding Z_s
- Hs → Linear_mean → μ
- Hs → Linear_var → σ
- z = μ + ε ⊙ σ (ε ~ N(0, I))
- 이 z가 바로 latent shape embedding = Zs
- Zs가 각 query - 결과적으로 encoder는 Q 포인트 중심의 shape feature를 생성함
- cross attention
- 포인트 샘플링
디코더 (latent vector → SDF → mesh)
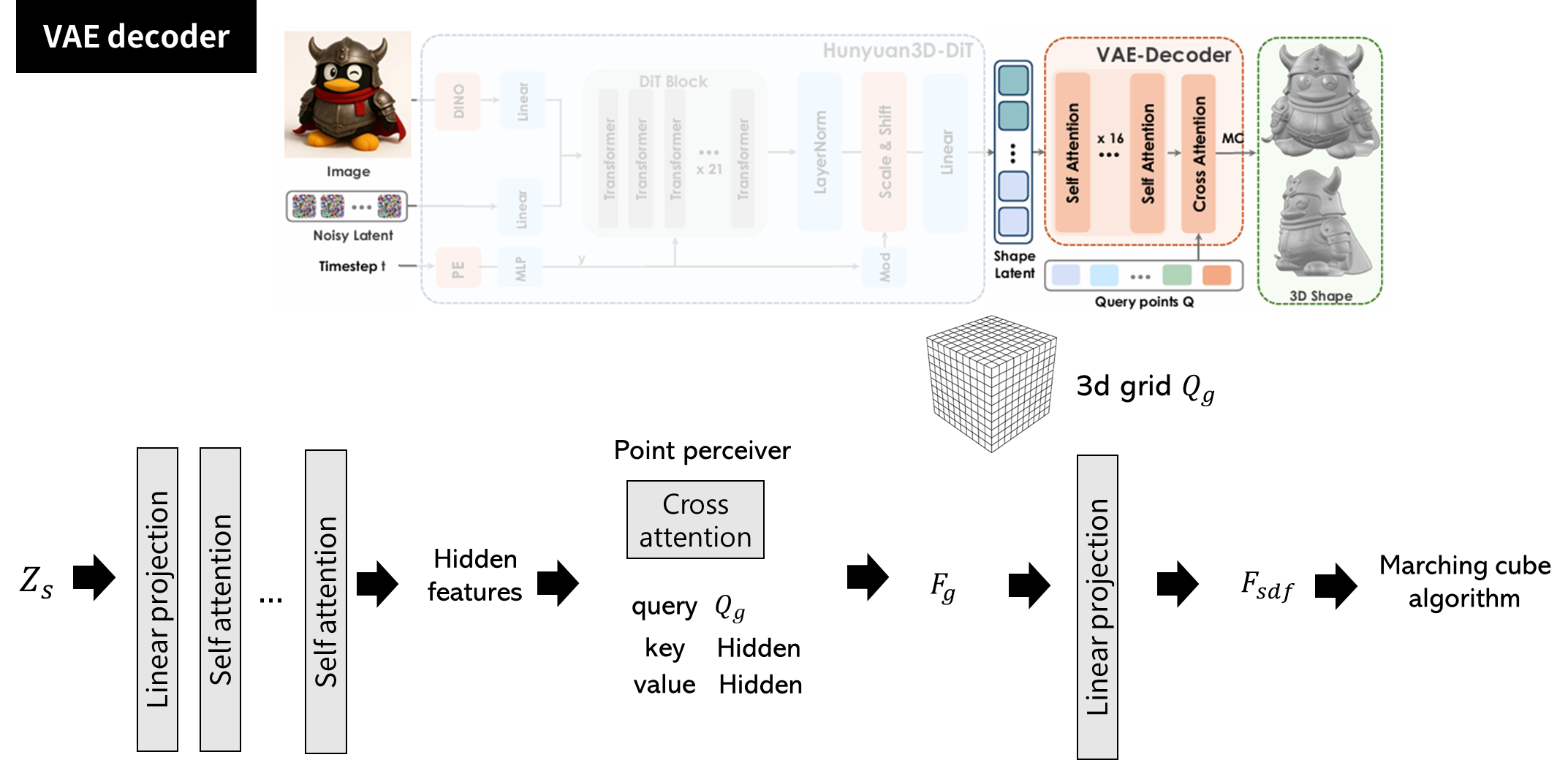
- Z_s → projection을 통해 transformer 입력 크기와 맞춰줌 → self attention으로 shape 정제
- 3d 공간 내 격자 쿼리를 통해 neural field F_g를 생성함
- 3D grid Q_g를 만듦 (H x W x D의 크기) 몇인지??
- 하나의 voxel 중심점이 하나의 query point가 됨
- point perceiver 모듈 (cross attention)
- query: Q_g, key/value: transformer hidden features (self attention 거친 latent vector)
- 각 grid point가 latent에서 필요한 정보를 끌어와서 neural field feature F_g를 생성함
- 각 grid point마다 d차원의 feature가 있는 형태
- linear projection을 통해 sdf 생성
- F_g를 하나의 스칼라값 F_sdf으로 예측함
- 각 3d grid 좌표에 대해서 sdf값을 예측하는 3d field를 생성하는 것
- marching cube 알고리즘 → 삼각형 mesh
- 0-level isosurface를 marching cube로 추출해서 메쉬 생성
- query points? 이 좌표의 SDF가 뭐야?를 수천~수만 개 좌표(query point)에 물어보면서 neural field를 채우는 방식 ⇒ SDF field를 얻음
학습 전략
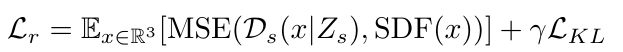
- reconstruction loss: 예측된 SDF와 정답 SDF 간의 MSE loss
- KL-divergence loss: latent vector가 연속적이고 압축적이 되도록 규제함 (정규화 목적)
- latent 분포가 너무 넓어지지 않게, 정규분포를 기준으로 만들도록 강제함
- 효율적인 학습을 위해서 latent token sequence length를 동적으로 조절함
- resolution이 높을 필요가 없을 때는 토큰 수를 줄이고, 복잡한 batch에서는 더 많은 토큰을 사용함
- 최대 latent 길이 3072
Hunyuan3D-DiT: image ↔ latent vector
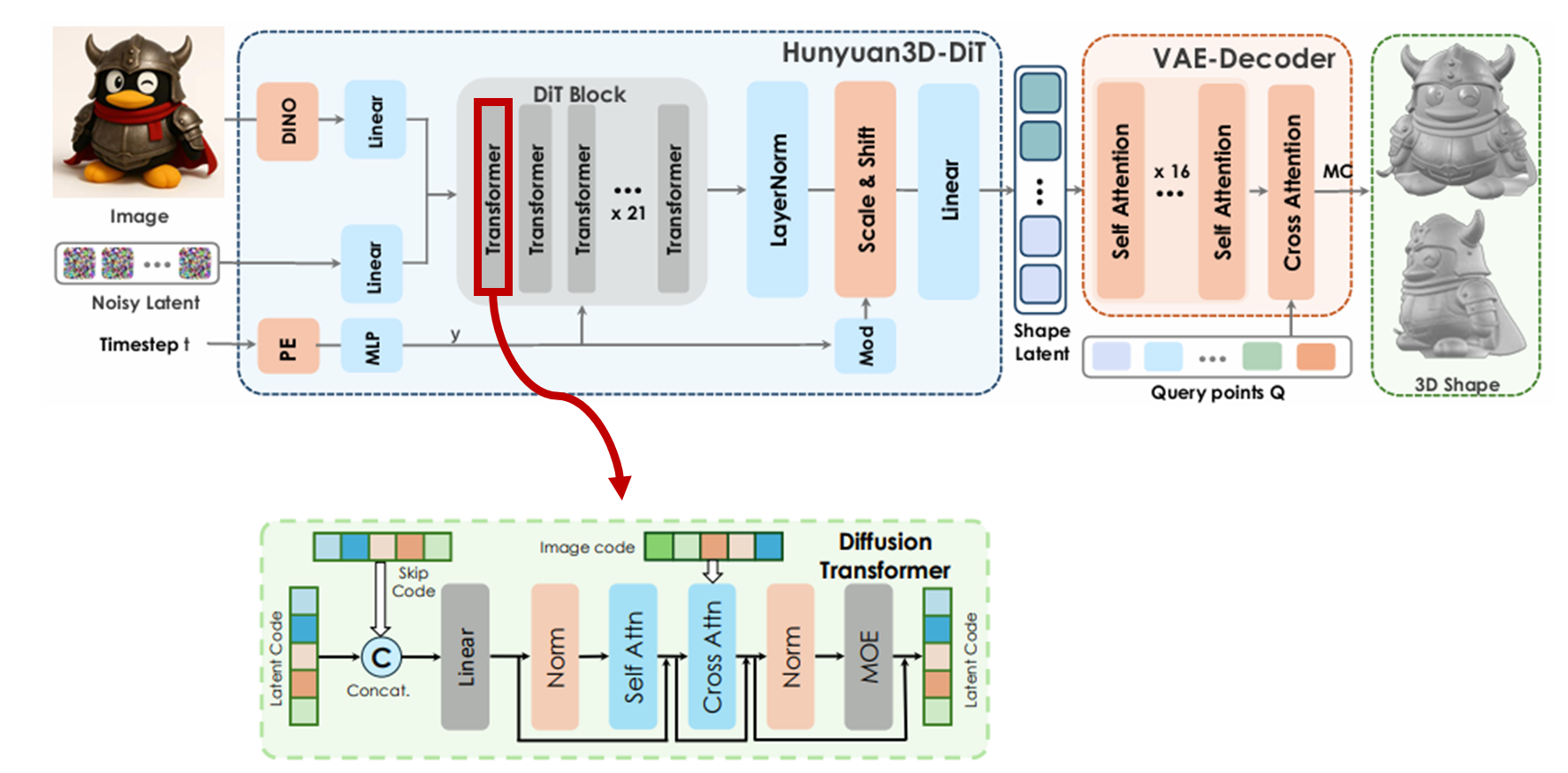
- 이미지 조건을 기반으로, detail하고 고화질의 3d 형상을 생성하는 flow 기반 diffusion 모델
- condition (image) encoder
- DINO v2 Giant
- 입력 이미지 518 x 518
- 배경 제거, resize, 중심 정렬, 배경 흰색으로 채우기
- DiT block - diffusion transformer 구조
- Hunyuan-DiT, TripoSG에서 dit 사용함
- 21개의 transformer layer를 쌓음
- skip connection을 통해서 이전 단계 latent랑 현재 feature를 concat함
- 이전 단계 latent? 이전 transformer layer의 latent
- 이미지 condition을 latent에 반영하기 위해서 cross attention 사용함
- query: latent code, key/value: image features
- moe: latent code의 표현력을 강화하기 위한 추가 모듈로 들어감
- 학습 전략
- 기존의 denoising diffusion 대신, flow matching 기반 학습
- flow matching: 가우시안 분포와 데이터 분포 사이의 확률 경로를 정의하고, 모델이 두 분포를 연결하는 속도장 (velocity field)를 예측하도록 학습함
- noise에서 data로 이동하는 속도장 (velocity field)를 학습
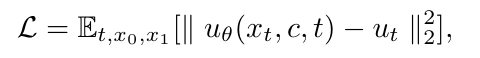
- 예측된 속도 u_θ와 참값 u_t를 비교해서 loss를 계산함
- ex. chair_0.obj가 있으면 shapevae를 통과시켜서 정답 latent vector를 구함 (x_1). 렌더링한 이미지를 조건으로 사용해서 랜덤 샘플링 x_0에서 x_1로 가는 방향을 학습함.
- 추론
- velocity를 따라가서 x_1을 복원하는 과정
- x_0을 가우시안 분포에서 랜덤 샘플링 → ODE 통합 (x_1을 계산) → latent embedding을 shapeVAE를 통해 3D 객체로 변환
Hunyuan3D-Paint
- 기존 컬러 텍스처만으로 리얼한 3d asset을 만들기에는 충분하지 않음
- 여러 뷰포인트에서 albedo(반사색), roughness(거칠기), metallic(금속성) 맵을 동시에 출력
- pbr 맵 3종
- 표면의 물리 기반 반사 속성을 모델링하면서 photorealism을 크게 강화
- 여러 뷰에서 동시 출력을 해서 텍스처의 일관성 보장
- 3d-aware RoPE 도입
- rotary positional embedding에 3d geometry-aware 정보를 추가함 (공간 정보를 주입)
- 뷰 간 일관성 증가, 텍스처 seam 제거, 3d-aware spatial alignment 강화
- rotary positional embedding에 3d geometry-aware 정보를 추가함 (공간 정보를 주입)
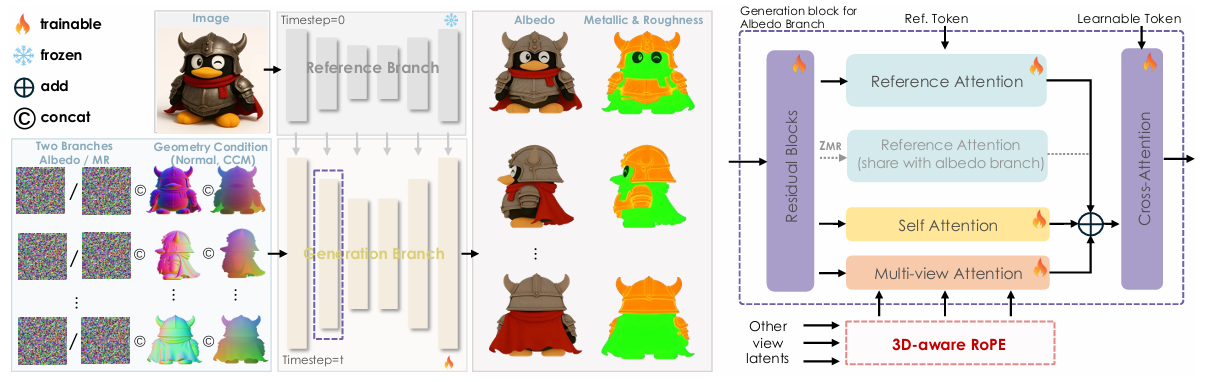
- 왼쪽: 전체 paint 모듈 파이프라인
Basic Architecture
- hunyuan3d-2 paint 아키텍쳐 기반에 새로운 material generation 프레임워크 제시함
- 기반 구조는 hunyuan2의 multiview 텍스처 생성 아키텍처
- 여러 뷰에서 동시에 텍스처를 생성
- Disney Principled BRDF model을 적용해서 고품질 pbr 머터리얼 맵을 생성함
- DBRDF 모델은 현재 영화/게임 업계에서 가장 널리쓰이는 pbr 재질 모델
- referenceNet의 기능 유지
- referenceNet: 입력 이미지(레퍼런스)의 high-level feature를 latent에 주입하는 모델
- normal map + ccm + latent noise를 concat
- ccm : 표면을 고유 좌표 공간으로 변환한 map
- multi-view 간 일관성을 확보하는데 중요함
- latent noise: 확률적 다양성을 위해서…
- ccm : 표면을 고유 좌표 공간으로 변환한 map
구조
- 입력: 레퍼런스 이미지, normal map, CCM, latent noise
- CCM: multi-view 간 매칭을 위한 고유 좌표
- 모델에 입력:
Noise + Normal Map + CCM + Reference Image Feature
- 출력: albedo map, metallic map, roughtness map
- 멀티채널 압축을 위한 VAE encoder
- 멀티채널? albedo, metallic, roughness
- vae encoder가 멀티채널 이미지를 latent 공간으로 압축하는 역할을 함
- Dual-branch UNet 구조
- 1️⃣albedo랑 2️⃣[Metal, Roughness]를 두 개의 Unet 브랜치로 독립적으로 예측함
- 1️⃣albedo Unet
- 레퍼런스 색상 정보 반영
- normal / ccm과 정렬
- multi-view consistency 유지
- 2️⃣Metal, Roughness
- 표면 반사를 모델링함
- albedo의 spatial 정보에 영향을 받음
- 둘 다 구조는 동일함
- Multi-attention 모듈
- 하나의 unet 블록에 3개의 attention이 병렬로 들어감
- self-attention
- multi-view attention
- 다른 view에서의 feature과 정렬
- reference attention
- 레퍼런스 이미지의 색감, 재질 정보를 latent에 주입
- albedo branch의 reference attention 출력을 MR branch로 전달함
- 물리적 일관성 확보를 위해…
→ 예: 금속 물체면 metallic=1 & 알베도도 금속스러운 색 → 두 맵이 spatial하게 어긋나지 않도록 강제
- 하나의 unet 블록에 3개의 attention이 병렬로 들어감
- 3d-aware RoPE 적용
- multi-view에서 texture seam/ghosting 발생함
- multi-view마다 공간 정보가 다르면 attention 정렬이 꼬이기 때문
- 3D 공간 기준으로 cross-view consistency를 강제하는 positional encoding
- multi-view에서 texture seam/ghosting 발생함
- illumination-invariant training
- 조명의 영향을 albedo와 mr이 받지 않도록
- 같은 객체를 서로 다른 조명으로 렌더링한 레퍼런스 이미지 두 세트를 가지고 consistency loss 적용
- Albedo(slot1) == Albedo(slot2) MR(slot1) == MR(slot2)
- 조명 변화와 무관하게 동일한 머터리얼 속성을 생성하도록 강제함
- VAE decoder로 최종 pbr texture map 복원
- dual branch unet이 예측한 latent를 decoder로 복원함
- 학습 세팅
- stable diffusion 2.1의 Zero-SNR checkpoint에서 학습 시작
- adamw optimizer lr 5e-5
- 2000 warm up step, 180 gpu-days (1개의 gpu로 몇 일의 학습이 걸렸는지)
Evaluation
- 3개의 task에 대한 실험: 3d shape generation (텍스처 x), texture synthesis, complete 3d asset 생성 (텍스처 o)
3d shape generation
- hunyuan3d-dit의 shape 생성능력을 평가함
metric- 목적: 생성된 메쉬와 입력 이미지 간의 유사도
- 3d: 8192 surface point를 뽑음
- text: vlm에 이미지를 넣고 캡션 얻음
- ULIP - ULIP-I (image-3d), ULIP-T (text-3d) 점수
- Uni3D - Uni3D-I (image-3d), Uni3D -T (text-3d) 점수
- 결과
- 오픈소스: Direct3D-S2, Step1X-3D, TripoSG
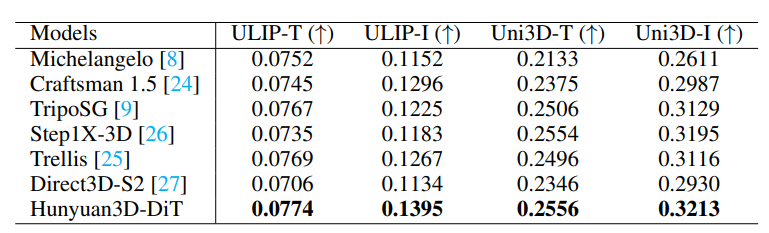
- hunyuan이 제일 성능 좋음
- 0.*% ~ 1% 정도. 큰 차이는 아닌듯
- (역시 3d-text보다 3d-image 유사도가 전반적으로 높음..!)
정성적 결과

- hunyuan이 입력 이미지와의 정합성이 높음, 세밀한 디테일을 잘 살림 (계산기 버튼 수… 등)
- 그리고 watertight mesh를 생성하는 능력 → ready for downstream applications
Texture map synthesis
- 텍스처 맵은 3d 에셋의 외관에 직접적으로 영향을 줌
- texture synthesis 모델과의 비교
- 생성된 텍스처와 GT와의 비교
metrics: FID, CLIP-based FID, LPIPSbaseline: SyncMVD-IPA, TexGen, Hunyuan3D2.0입력: 텍스처 없는 메쉬, 이미지
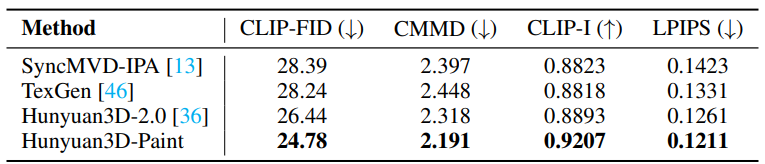

- image-to-3d 모델과의 비교
- texture 포함한 complete 3d 생성능력을 평가
- baselines
- 공개된 3d 생성 모델: Step1X-3D, 3DTopiaXL
- 상업용 모델 1, 2
- end-to-end 품질을 비교함
- hunyuan이 가장 사실적인 pbr을 만들뿐 아니라 low quality geometry에서 오는 단점을 완화함 → 가장 성능 좋음!

Conclusion
- hunyuan2.1는 혁신적인 production-ready 3d content 생성 방법을 제시함
- 고품질 geometry 생성 + pbr material 생성
- 오픈소스
- shape 생성에 DiT, texture 생성에 multi-view conditioned painter를 사용함으로써, 스튜디오 퀄리티의 에셋을 빠른 속도로 생성할 수 있게 되었음
- 전체 과정 (학습 전처리, 학습, 가중치 등..)을 오픈소스로공개 → 더 많은 사람들에게 접근 가능하게 함으로써 여러 산업에 혁신
- 정량적 지표를 통해 우수함 증명함
- pbr-textured 3d asset 생성에서는 처음으로 오픈소스 → academic research와 sclable content 생성 간의 gap을 메우고, 글로벌 오픈 협업을 촉진함
This post is licensed under CC BY 4.0 by the author.